
目次
はじめに
「この広大な宇宙に地球と似たような惑星はあるの?」
「もしあるのあればそこに住んでいる生命体はどんな姿をしているの?」
そんなことを考えたことはありませんか?
この人類最大の謎に挑戦していたのがNASAの打上げた人工衛星「kepler」です。
kepler衛星はこれまでにたくさんの惑星を発見しています。
今回はkeplerのデータを使って第二の地球を機械学習を使って探してみたいと思います!

「kepler」が発見した太陽系外惑星「ケプラー186f」の想像図
(提供:NASA/Ames/JPL-Caltech/T. Pyle)
kepler衛星とは
2009年にNASAが打上げた大型の人工衛星で、地球型の太陽系外惑星を見つけることをメインミッションとしていました。
kepler衛星は打上げられてから9年間で50万個以上の星を観測し、2600個以上の惑星を発見しています。
残念ながら2018年10月に燃料が尽きたため運用を終了したとNASAは発表しました。

「kepler」衛星のイラスト(提供:NASA/Ames/Dan Rutter)
どうやって太陽系外惑星を見つけるの?
私は天文学の専門家ではありませんので、正確な説明は出来ませんが、イメージが沸くようにざっくりと概要だけ記載します。
太陽系外惑星の発見方法にはいくつかありますが、kepler衛星は”トランジット法”と呼ばれる観測手法を使っていました。
トランジット法とは、惑星が恒星の手前を通過すると、恒星の明るさがわずかに暗くなります。その微小な明るさの変化を捉える手法です。
また、トランジット法は惑星の大気組成を求めることも出来るそうです。
惑星が恒星面を通過すると、恒星の光の一部は惑星の上層大気を通過するため、その際の恒星の高解像度のスペクトル分析をすることで大気成分を特定出来るという原理です。
系外惑星探査を専門でやられていた方がいらましたら、是非色々とご教示ください。
スポンサーリンク![]()
今回チャレンジしたコンペ
さて、今回はExoplanet Hunting in Deep Spaceというkaggleのコンペからkeplerで観測されたデータを使いました。
データの可視化
このコンペではあらかじめトレーニングデータとテストデータがCSV形式で用意されていますので、まずはそれらを読み込みます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt data_path = "./" train = pd.read_csv(data_path+"exoTrain.csv") test = pd.read_csv(data_path+"exoTest.csv")</pre> <pre class="lang:python decode:true " title="kepler_train_head">train.head()</pre> <img class="alignnone size-large wp-image-482" src="https://techtech-sorae.com/wp-content/uploads/2019/03/kepler_trainHead-1024x227.jpg" alt="" width="525" height="116" /> </div> <pre class="lang:python decode:true " title="kepler_testHead">test.head()
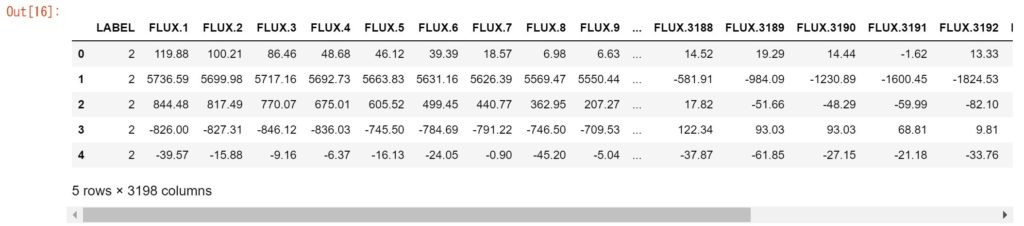
カラム:LABELは2が太陽系外惑星で、1が太陽系外惑星ではないことを表しています。
fluxはkeplerが観測した星の光の強度です。
今回はfluxから系外惑星が否かを推定したいので、LABELはパラメータから外しておきます。
X_train = train.drop('LABEL', axis=1)
y_train = train.LABEL
X_test = test.drop('LABEL', axis=1)
y_test = test.LABEL
次に、系外惑星のfluxをグラフ化してそこから何か特徴が無いかを見ていきます。
for i in range(4):
Y = X_train.iloc[i]
X = np.arange(len(Y))
plt.figure(figsize=(15,5))
plt.ylabel('Flux')
plt.xlabel('Observation')
plt.plot(X, Y)
plt.show()
![]()
う~む、、私レベルの知識ではこのグラフから特徴を見出すことは難しそうです。
分かることと言えば、系外惑星と言っても星の光の強度は全然異なる…ことくらいですかね。。
本当は何か前処理等してあげると精度良くなるのかもしれないけど、どのような前処理が妥当かも見当つかなかったため、とりあえずこの生データをアルゴリズムに突っ込んでみます。
モデルの生成・精度検証
今回は星の光の強度スペクトルを使って、系外惑星か否かという二値の分類問題ですので、分類モデルを作って精度検証してみます。
試したアルゴリズムは下記の通りです。
・KNN
・ロジスティック回帰
・決定木
・ランダムフォレスト
・勾配ブースティング
・多層ニューラルネットワーク
・サポートベクターマシン
また、評価指標は正解率としました。
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
# set pipelines for different algorithms
pipelines = {
'knn':
Pipeline([('scl',StandardScaler()),
('est',KNeighborsClassifier())]),
'logistic':
Pipeline([('scl',StandardScaler()),
('est',LogisticRegression(random_state=1))]),
'rsvc':
Pipeline([('scl',StandardScaler()),
('est',SVC(C=1.0, kernel='rbf', class_weight='balanced', random_state=1))]),
'lsvc':
Pipeline([('scl',StandardScaler()),
('est',LinearSVC(C=1.0, class_weight='balanced', random_state=1))]),
'tree':
Pipeline([('scl',StandardScaler()),
('est',DecisionTreeClassifier(random_state=1))]),
'rf':
Pipeline([('scl',StandardScaler()),
('est',RandomForestClassifier(random_state=1))]),
'gb':
Pipeline([('scl',StandardScaler()),
('est',GradientBoostingClassifier(random_state=1))]),
'mlp':
Pipeline([('scl',StandardScaler()),
('est',MLPClassifier(hidden_layer_sizes=(3,3),
max_iter=1000,
random_state=1))])
}
# fit & evaluation
scores = {}
for pipe_name, pipeline in pipelines.items():
pipeline.fit(X_train, y_train)
scores[(pipe_name,'train')] = accuracy_score(y_train, pipeline.predict(X_train))
scores[(pipe_name,'test')] = accuracy_score(y_test, pipeline.predict(X_test))
pd.Series(scores).unstack()
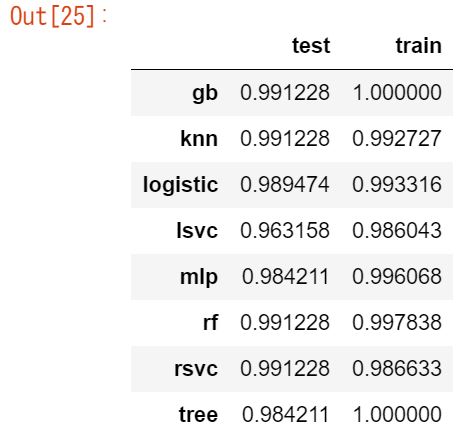
結果を見てみると、まずは未知のデータ(テストデータ)に着目してみると、どのアルゴリズムでも良い精度が出ていることが確認できます。
トレインデータとの差もほとんどなく、過学習もしていなさそうです。
生データを突っ込んでアルゴリズムで力技的に分類してみましたが、なかなか良い結果が得られました。
最後に
kepler衛星のデータを使って系外惑星か否かを分類するタスクにチャレンジしてみました。
生データをそのまま使っても精度良い結果が得られました。
他の方のカーネルを見てみると、フーリエ変換を前処理として行っていたりしていましたが、星の観測データの分野ではどのように前処理しているのでしょうか?
ここらへんの知見があるともっと良いやり方(王道的なやり方)があるのでしょうか?
ちなみに、kepler衛星データの最新の分析によると、夜空に見える恒星の20%~50%には地球と同じくらいの岩石惑星は液体の水を惑星の表面に持つかもしれないと結論づけられているようです。
水があるということは生命体がいる可能性もありますよね!
とてもロマン溢れるデータ分析でした。
今後の研究に期待しましょう!
