
顔写真からジャニーズ系かEXILE系かを判定する学習モデルを作成してみました。
全3回の記事の予定です。
本記事は、「テスト・評価(データ増量)」 (記事 3/3)を掲載しています。
目次
はじめに
Udemy![]() の機械学習講座を受講し終わったので、成果物として作ってみました。
の機械学習講座を受講し終わったので、成果物として作ってみました。
詳細なソースコードはGitHubに上げていますので、よろしければそちらを参照ください。
また、これまでに書いた記事は下記を参考ください。
また、これまでに書いた記事は下記を参考ください。
動作環境
・Anaconda 3
・TensorFlow (CPU版)
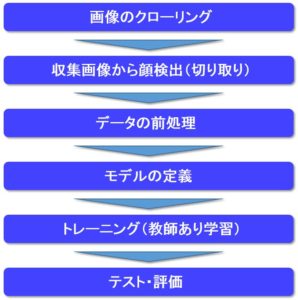
全体の処理フロー
全体の処理フローを下図に記します。
本記事では、「テスト・評価(データ増量)」について説明していきます。
精度向上を目指して試してみたこと
・Epoch数を増やす
・データの水増し
Epoch数増加による精度結果
まずは入力に使う画像データはそのままで単純にEpoch数を増加してみました。
その前に深層学習におけるEpoch数について少しおさらいしておきましょう。
コードでいうと、下のfit関数の引数epochsになります。
model.fit(x, y, batch_size=32, epochs=25)
Epoch数とは、「1つの訓練データを何回繰り返して学習するのか」ということです。
ちなみにBatchサイズとは、「一回に処理する件数」のことです。
またデータを選ぶ際はランダムで選び出します。
上のコードの場合は「Batchサイズ=32」,「Epoch数=25」ですので、
これは一回の処理で32件ずつデータを処理して、これを25回(学習を)繰り返すということになります。
それならまずは力技で学習回数を増やしてみよう!っということでその結果がこちら。
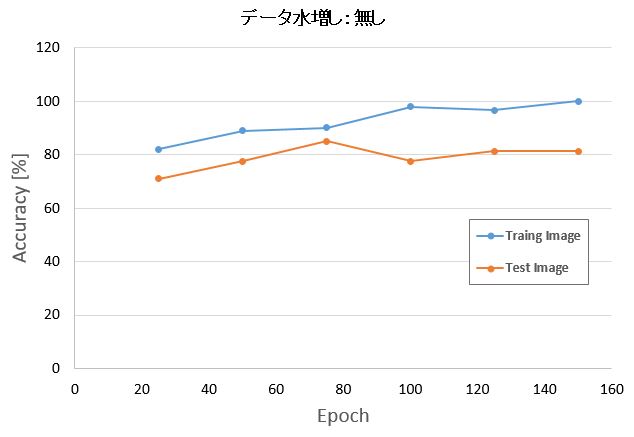
Epoch数:25 -> テスト画像 Accuracy:71%
Epoch 数:150 -> テスト画像 Accuracy:81%
トレーニング画像はEpoch数の増加と共に精度が良くなっています。
しかし、テスト画像はトレーニング画像ほど精度向上はしていないことがわかりました。
それでも今回の場合は単純にエポック数を増やしただけで精度は約10%程度向上することが出来ました。
データの水増しによる精度結果
次に入力画像のデータを増やしたときの精度が向上するか試してみました。
データを水増しするときによく使う手段として、
元の画像を画像処理で疑似的にデータ量を増やすことです。
今回は元の画像について下記の条件を加えることでデータ量を増やしました。
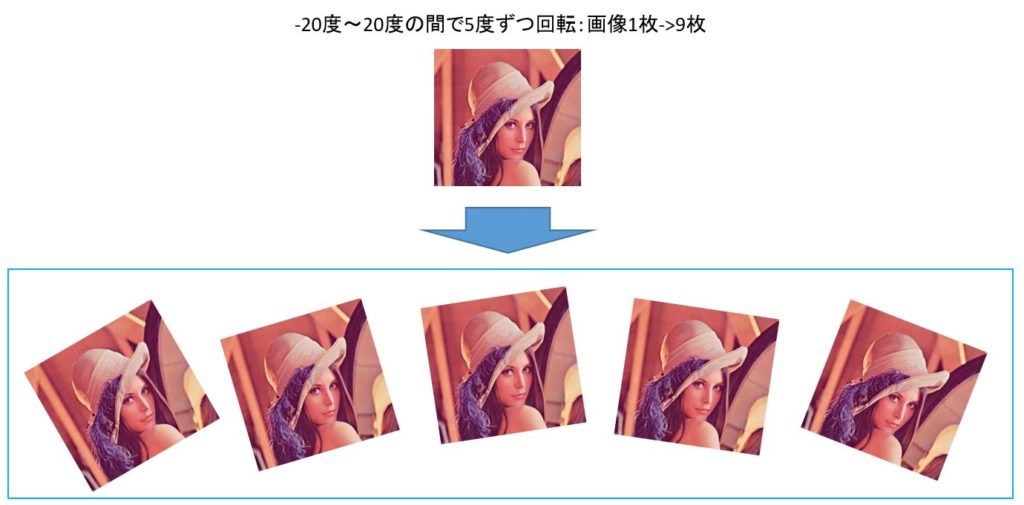
・画像の回転
今回は画像一枚一枚について-20度~20度までの範囲で5度ずつ回転を加えてみました。
そうすることで、画像1枚が画像9枚に増やすことが出来ます。
イメージはこちら。
(ジャニーズやEXILEの方の画像を載せると著作権的に怖かったので、Lennaさんにさせていただきました。)
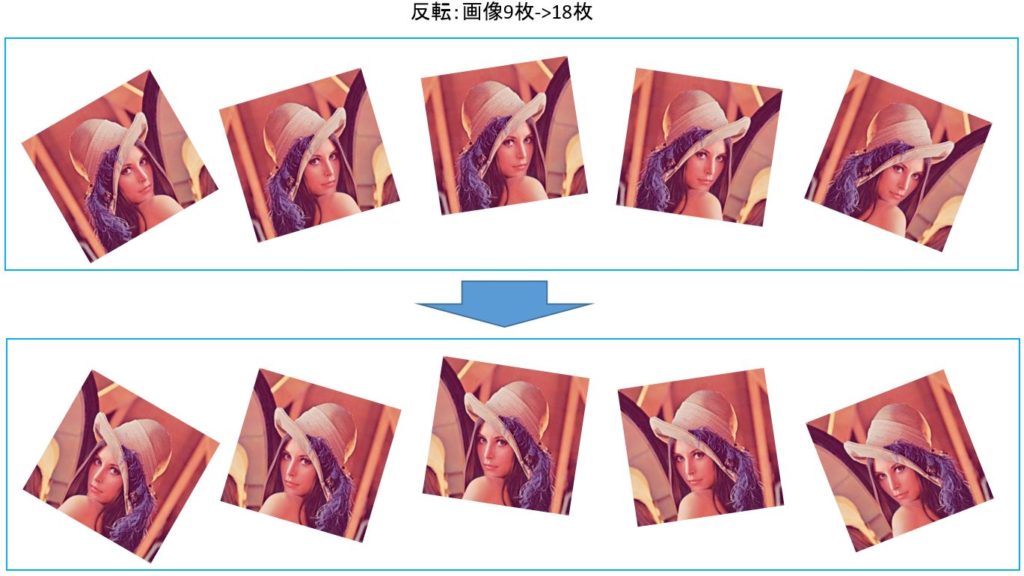
・画像の反転
次に回転した画像に対して反転して、画像9枚から18枚に増やします。
イメージはこちら。
この二つの処理を加えることで、画像1枚に対して18枚にデータを増やすことが出来ました。
ソースコードはこちら。
from PIL import Image
import os, glob
import numpy as np
from sklearn import model_selection
classes = ["exile", "johnnys"]
num_classes = len(classes)
image_size = 50
num_testdata = 100
X_train = []#画像の配列データ
X_test = []#ラベル
Y_train = []
Y_test = []
for index, classlabel in enumerate(classes):
photos_dir = "./" + classlabel
files = glob.glob(photos_dir + "/*.jpg")
for i, file in enumerate(files):
if i >= 160: break#収集した画像の最小数
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
if i < num_testdata:
X_test.append(data)
Y_test.append(index)
else:
for angle in range(-20, 20, 5):
# 回転
img_r = image.rotate(angle)
data = np.asarray(img_r)
X_train.append(data)
Y_train.append(index)
# 反転
img_trans = img_r.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trans)
X_train.append(data)
Y_train.append(index)
# tensorflowが扱いやすいnumpy配列に変換
x_train = np.array(X_train)
x_test = np.array(X_test)
y_train = np.array(Y_train)
y_test = np.array(Y_test)
xy = (x_train, x_test, y_train, y_test)
np.save("./judge_exile_johnnys_aug.npy", xy)
では、データ水増しをして学習結果を見てみましょう。
Epoch数は25で学習させます。
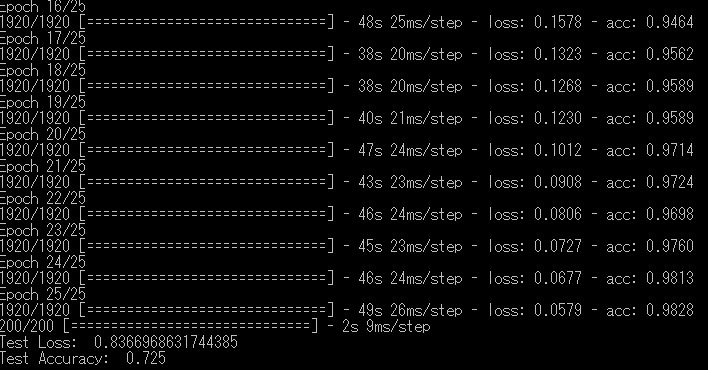
データ水増し無しのときの精度は71%だったので、それと比べて1.5%しか精度向上しませんでした。
まとめ
・Epoch数を増やすことでおよそ10%程度、精度向上出来た。
・データ水増し(画像の回転、反転)有りのときは無しに比べておよそ1.5%精度が向上。
簡単な考察
画像収集した際に、画像サイズが小さいものもクローリングしていました。
その画像から顔検出してリサイズすると画質が悪くなってしまっていました。モザイクがかかったような状態ですね。
前処理している段階でこのような画像データがちらほら見受けられたので、もう少し画質が良いデータを揃えないと精度上がらないかもしれません。
ただ、良質なデータ収集という意味ではネットから闇雲に収集しても限界があるでしょうね。。
うーむ。画像認識、奥が深い。
他に良い手法を考え付いたらまた更新したいと思います。
参考
スポンサーリンク
![]()