
本記事は、画像のクローリングと画像から顔を切り取る処理まで(記事 1/3)を掲載しています。
目次
はじめに
顔写真から、乃木坂46系かAKB48系か一般人系か判定する学習モデル作ってみた
この記事を見て私が似たようなことで思い浮かんだのが、ジャニーズ系とEXILE系でした。
詳細なソースコードはGitHubに上げていますので、よろしければそちらも参照ください。
モチベーション
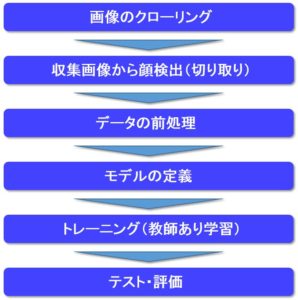
全体の処理フロー
本記事では、「画像のクローリング」と「収集画像から顔検出(切り取り)」について説明していきます。
画像のクローリング
しかし、両方ともいっぱいグループがあるけど、どのグループを教師データとして代表させるか?
ネットの情報などから、今回は人気がありそうな3つのグループを代表とさせていただきました。
ファンの方からすればいろいろと異論等あると思いますが、あくまで画像認識の学習の一環としていることを理解していただけると助かります。
・「EXILE系」:EXILE、三代目 J SOUL BROTHERS、GENERATIONS
代表グループが決定したので、画像の収集を行います。
APIによるクローリングは現在色々と厳しくなっているようで悩みました。
結果的に、こちらのサイトのソースコードをそのまま引用させていただきました。
API を叩かずに Google から画像収集をする
最後の引数の数字は収集する枚数です。
# -*- coding: utf-8 -*-
import json
import os
import sys
import urllib
from bs4 import BeautifulSoup
import requests
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})
def search(self, keyword, maximum):
print('begin searching', keyword)
query = self.query_gen(keyword)
return self.image_search(query, maximum)
def query_gen(self, keyword):
# search query generator
page = 0
while True:
params = urllib.parse.urlencode({
'q': keyword,
'tbm': 'isch',
'ijn': str(page)})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
def image_search(self, query_gen, maximum):
# search image
result = []
total = 0
while True:
# search
html = self.session.get(next(query_gen)).text
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
imageURLs = for js in jsons]
# add search result
if not len(imageURLs):
print('-> no more images')
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
print('-> found', str(len(result)), 'images')
return result
def main():
google = Google()
if len(sys.argv) != 3:
print('invalid argment')
print('> ./image_collector_cui.py [target name] [download number]')
sys.exit()
else:
# save location
name = sys.argv[1]
data_dir = 'temp_image_data/'
os.makedirs(data_dir, exist_ok=True)
os.makedirs('temp_image_data/' + name, exist_ok=True)
# search image
result = google.search(
name, maximum=int(sys.argv[2]))
# download
download_error = []
for i in range(len(result)):
print('-> downloading image', str(i + 1).zfill(4))
try:
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
print('--> could not download image', str(i + 1).zfill(4))
download_error.append(i + 1)
continue
print('complete download')
print('├─ download', len(result)-len(download_error), 'images')
print('└─ could not download', len(
download_error), 'images', download_error)
if __name__ == '__main__':
main()
-収集画像のごみデータ削除
イラスト画像やロゴしか写っていなかったりと。
ここが一番めんどくさて地味な作業。。
ちなみに私はジャニーズの画像からこの作業をしているところを、奥さんに見られてしまい、「頭おかしくなった?」と言われてしまいました。
収集画像から顔検出(切り取り)
関係ない画像のスクリーニングが終わったところで、顔検出をやってみたいと思います。
さすがにこれだけのデータからPhotoshopとかを使って一枚一枚顔の切り出しはやりたくなかったので、みんながお世話になってるOpenCVを使うことにしました。
# -*- coding: utf-8 -*-
import cv2, os, sys
def detect_face(img_path, cascade_path, dir, file, image_size):
#ファイル読み込み
image = cv2.imread(img_path)
re_file_name = dir + "_" + file
print("Detect face: ", re_file_name)
#グレースケール変換
if len(image.shape) == 3:
height, width, channels = image.shape[:3]
else:
height, width = image.shape[:2]
channels = 1
if (channels == 3):
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#カスケード分類器の特徴量を取得する
cascade = cv2.CascadeClassifier(cascade_path)
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
#facerect = cascade.detectMultiScale(image_gray)
if len(facerect) > 0:
for rect in facerect:
dst = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
dst = cv2.resize(dst, dsize=(image_size, image_size))
cv2.imwrite("./face_all/" + re_file_name, dst)
def main():
image_size = 50
#HAAR分類器の顔検出用の特徴量
cascade_path = "C:/Anaconda/envs/tf140/Lib/site-packages/cv2/data/haarcascade_frontalface_alt.xml"
# オリジナル画像のディレクトリ
org_img_path = "./temp_image_data/"
dirs = []
for i in os.listdir(org_img_path):
if os.path.isdir(org_img_path + i):
dirs.append(i)
if len(dirs) == 0:
print("not exist original image direcotry")
sys.exit()
# フォルダごとのループ処理
for dir in dirs:
each_dir_path = org_img_path + dir + "/"
# 画像ファイルごとのループ処理
for file in os.listdir(each_dir_path):
each_img_path = each_dir_path + file
detect_face(each_img_path, cascade_path, dir, file, image_size)
print("Finish detect face")
if __name__ == "__main__":
main()
そして、ここでもまたごみデータが発生してしまいます。
ここがめんどくさて地味な作業。。
私の場合ですと、最終的に残った顔画像は、
「EXILE系」:173枚
本記事はここまで。
参考
![]()
