
目次
はじめに
Udemyの深層学習コースを受講したので、その成果物として記事にしました。
今回やったことは「ニューラルネットワークを用いたワイン分類」です。
ソースコード本体はGitHubにあげましたので、良ければこちらもどうそ。
Udemyとは
本題に入る前に今回の学習に用いた「Udemy」について簡単にご紹介します。
「Udemy」はアメリカのオンライン教育プロットフォームで動画で学習できるサービスです。
ユーザーが勉強したい分野の講座を購入して、動画形式で学習を進めることが出来ます。
動画形式なので説明もわかりやすく初学者の学習には最適なサービスです。
使用するデータセット
・scikit-learnに含まれるワインのデータセット
やったこと
scikit-learnのワインデータセットには、13個の特徴量の組み合わせおよびワインの種類(三種類の分類ラベル:0, 1, 2)が用意されています。
ただし、今回は問題を簡単化するために二種類の分類ラベル(0,1)を用いて二分類による分類を行いました。
また、特徴量群はトレーニング用とテスト用で分離をし、精度がどのくらいなのかを確認しました。
スポンサーリンク

動作環境
・Anaconda3
・PyTorch
作成モデル
今回は下記のようなニューラルネットモデルを作成して、ワインの分類分けを行います。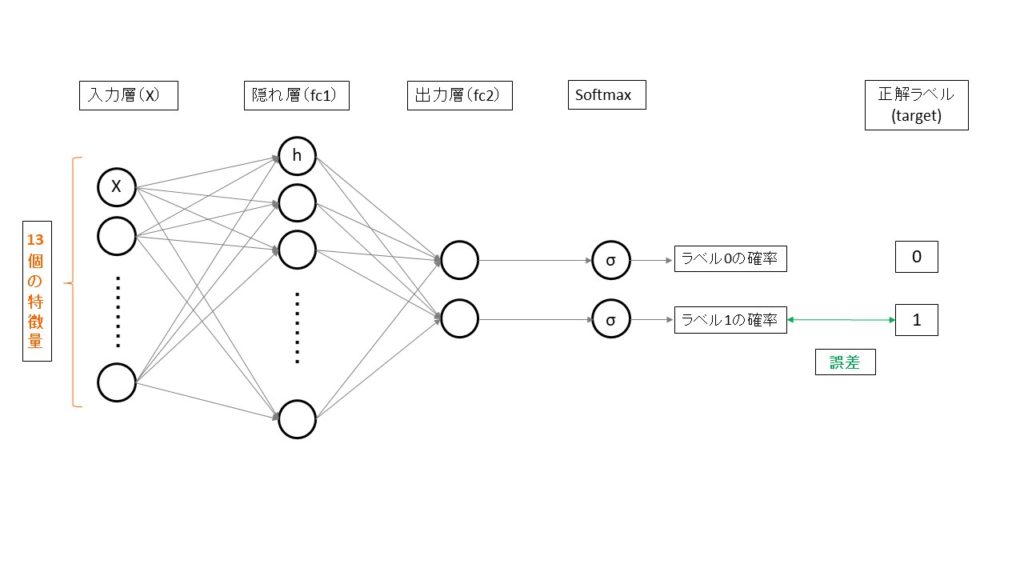
必要なライブラリのインポート
今回はPyTorchを使いますので、必要なライブラリのインポートを行います。
import torch from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset</pre> <span style="font-family: arial, helvetica, sans-serif;">続いて、scikit-learnとpandasのライブラリのインストールを行います。</span> <pre class="lang:python decode:true" title="import2">from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split import pandas as pd
データセットの読み込み
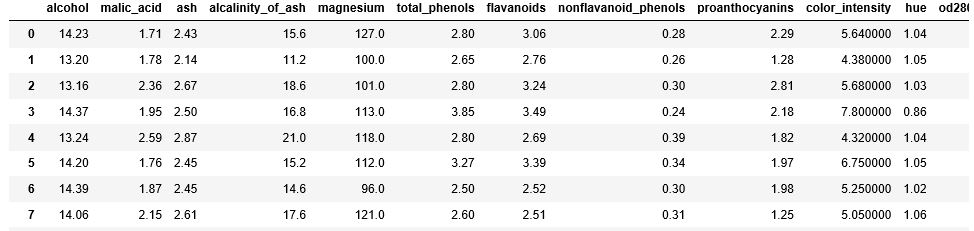
全部で177件のデータが入っていて、13種類の特徴量(属性)が入っていることが確認できます。
wine = load_wine() pd.DataFrame(wine.data, columns=wine.feature_names)
データセットの’target’を確認してみると、0~2までの値が入っています。今回は二分類の問題としますので、0,1のクラスだけに分ける操作をします。
0,1のクラスは129番目と確認出来ますので、そこまでを切り出して格納します。
wine_data = wine.data[0:130] wine_target = wine.target[0:130]
続いて、トレーニング用のデータとテスト用のデータに4:1に分けます。
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size = 0.25)
PyTorchへのテンソル(多次元行列)への変換
まずはトレーニングデータとテストデータをnumpy形式からPyTorchのテンソルへの変換をします。
特徴量を格納するデータの形式は浮動小数点数(float)にし、正解ラベルは整数型(long)として格納します。
train_X = torch.from_numpy(train_X).float() train_Y = torch.from_numpy(train_Y).long() test_X = torch.from_numpy(test_X).float() test_Y = torch.from_numpy(test_Y).long()
確認してみると、確かに13個のデータのテンソルと二番目の要素に正解ラベルの「0」が入っています。
train=TensorDataset(train_X, train_Y) train[0]

続いて、DataLoaderを使ってミニバッチ(少ない量のデータの塊)に分けてモデルに複数回入れることが出来るように準備をします。
今回はデータを15個に分けて、更にデータをシャッフルさせます。
train_loader = DataLoader(train, batch_size=15, shuffle=True)
モデルの定義
今回の場合は入力層が13個(特徴量分)あり、中間層を128に設定しました。
次の結合層は入力層が前の中間層の128となり、出力層は2分類ですので、2と設定します。
また、活性化関数はReLU関数を通して、ソフトマックス関数を適用した値を返します。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 128)
self.fc2 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x)) # ReLU: max(x, 0)
x = self.fc2(x)
return F.log_softmax(x, dim=0)
最後に、model変数を定義して、上記のモデルのインスタンスを格納します。
model = Net()
トレーニング
今回は損失関数をクロスエントロピーロスを使い、最適化するアルゴリズムを確率的勾配効果法(SGD)を使います。
また、エポック数は500回としてトレーニングします。
オプティマイザーは、最初に初期化(0)をして学習します。
※初期化を行わないとランダムな数が入力されてしまい学習が上手くいきませんので注意が必要です。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(500): #学習回数500回
total_loss = 0
for train_x, train_y in train_loader:
train_x, train_y = Variable(train_x), Variable(train_y)
optimizer.zero_grad()
output = model(train_x)
loss = criterion(output, train_y)
loss.backward()
optimizer.step()
total_loss += loss.item() #loss.data[0]で記述するとPyTorch0.5以上ではエラーが返る
if (epoch+1)%60 == 0:
print(epoch+1, total_loss)
結果を見てみると、最終的な損失関数は4.8520となったことがわかります。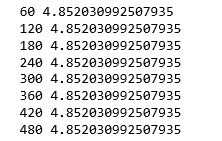
精度計算
最後にテストデータを使って精度検証します。
精度検証では、PyTorchに含まれるmax関数を使います。
これはモデルにテストデータを入れて値の大きいほうを取得する関数です。
そして、最終的な精度計算は、正解と一致していたら1を加算してデータ数で除算して平均値として計算します。
test_x, test_y = Variable(test_X), Variable(test_Y) result = torch.max(model(test_x).data, 1)[1] accuracy = sum(test_y.data.numpy() == result.numpy()) / len(test_y.data.numpy())
次はニューラルネットを多層化してみることで精度向上するか試してみます。
ニューラルネットワークの多層化(ディープラーニング)による精度検証
イメージとしては、下記の様になります。
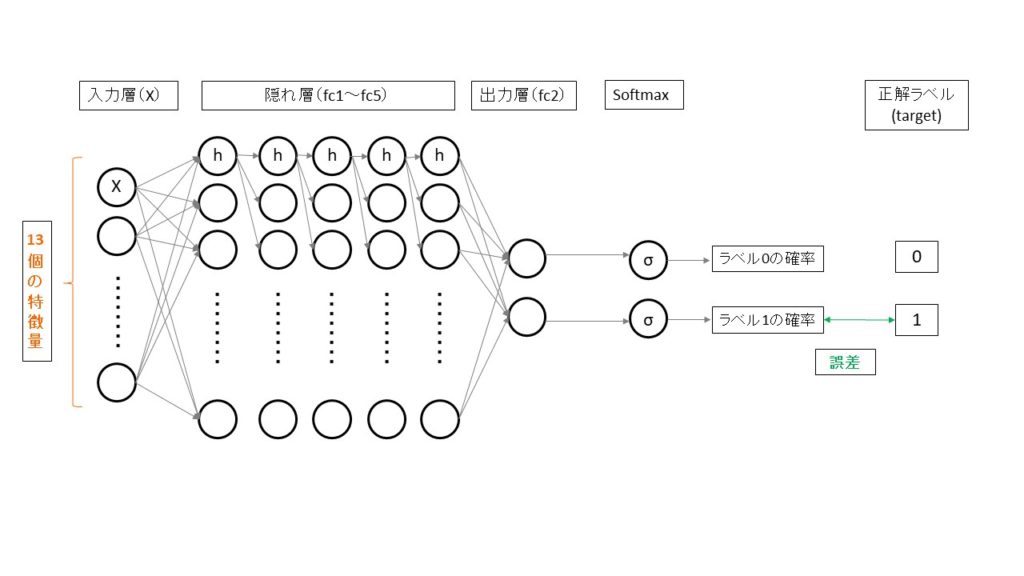
多層化するためにモデルの定義を次のように変更を加えます。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 128)
self.fc4 = nn.Linear(128, 128)
self.fc5 = nn.Linear(128, 128)
self.fc6 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x)) # ReLU: max(x, 0)
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = F.relu(self.fc5(x))
x = self.fc6(x)
return F.log_softmax(x, dim=0)
トレーニングの結果、損失関数が1.44となったことがわかります。
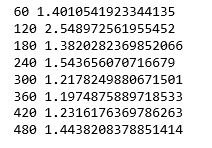
最後に精度計算してみます。
その結果、およそ90%となり、3層のニューラルネットワークよりもおよそ40%向上したことがわかりました。
![]()
これらのパラメータチューニングをすることで更に精度向上をさせることが出来るかと思います。
まとめ
今回はscikit-learnに含まれるワインのデータセットを用いてPyTorchを使って二分類してみました。
今回独習にするにあたって用いたUdemy![]() はほんとにオススメなサービスです。
はほんとにオススメなサービスです。
私はこれまでは主にKerasを使って深層学習に関する勉強やプロダクト開発を行っていたのですが、今回初めてPyTorchで深層学習を試すことが出来ました。
その他にも機械学習や統計学、Webアプリ作成など幅広いコンテンツが提供されていますので、初学者の方は一度試されてみてはいかがでしょうか。
参考書籍

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
人気記事
