
目次
はじめに
Pythonと便利なScheduleライブラリを使って定期実行可能なWebスクレイピングをやってみます。
意外とこの組み合わせの記事が見つからなかったので、記事に残しました。
ソースコードはGitHubにもアップしています。
注意事項
Webスクレイピングの注意事項です。
Webスクレイピングをやるさいには下記のサイト等をよく読んでマナーを守って楽しみましょう。
また万が一、本記事で紹介したプログラムによって何か問題が発生した場合でも
その生じたいかなる損害に関しても、責任は負いかねますのでご了承ください。
動作環境
・Python 3.7.1
やること
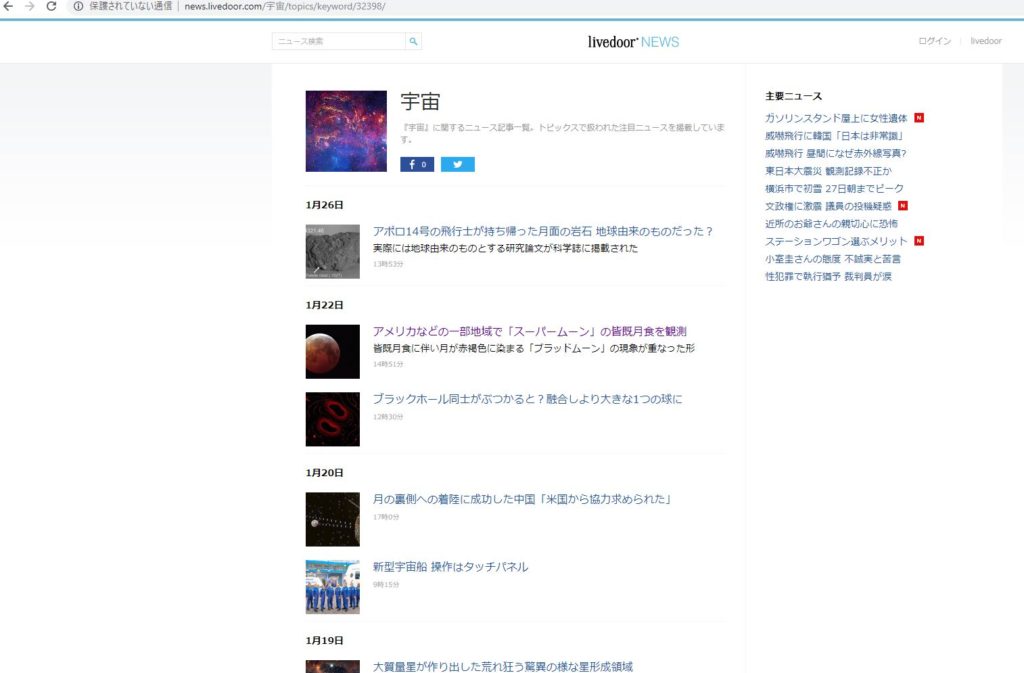
最新の「宇宙」ニュースを定期的に取得し、CSVファイルに出力。
今回はlivedoorニュースの宇宙記事のページからスクレイピングしてみます。
ライブラリのインストール
定期的にスクレイピングしたいので、今回は便利なライブラリであるscheduleをインポートしておきます。
その他スクレイピングで定番なurllibやBeautifulsoupもインポートします。
import urllib.request, urllib.error from bs4 import BeautifulSoup from datetime import datetime import schedule import pandas as pd import time
取得したいコンテンツの確認
Google chromeブラウザでlivedoorの宇宙記事のページ上で右クリックして、”検証”クリックします。
そうするとこのWebサイトのソースコードを確認できるようになります。
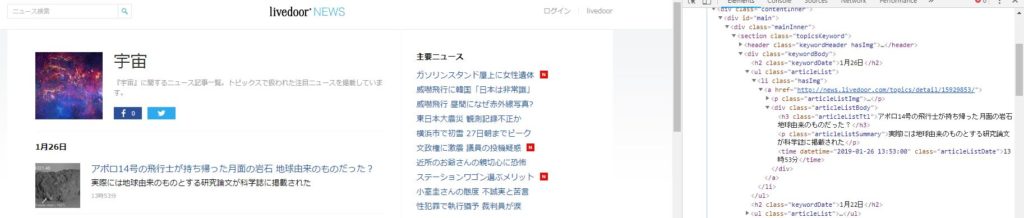
このコードから取得したい情報を検索します。
今回の場合、<li class …>に必要な情報が格納されていることがわかったので、
soup.find_allでliクラスの要素を全て抽出します。
そして取得したliクラスの中でさらに必要な部分だけを抜き出してきます。
# 現在時刻を取得
nowTime = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
url = "http://news.livedoor.com/%E5%AE%87%E5%AE%99/topics/keyword/32398/"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
# コンテンツを取得
contents = soup.find_all("li")
columns = ["GetInformationDate", "Topic", "Link"]
df = pd.DataFrame(columns = columns)
print(nowTime)
for content in contents:
topic = content.find('h3')
if (topic != None):
link = content.find('a')
detailLink = link.get('href')
print('Title :' + str(topic.text) + 'Link :' + detailLink)
_csv = pd.Series([nowTime, str(topic.text), detailLink], columns)
df = df.append(_csv, columns)
scheduleライブラリで簡単に定期処理
今回は定期的にスクレイピング処理をしたいので、scheduleライブラリで簡単に処理します。
# 10分毎にjobを実行
schedule.every(10).minutes.do(task)
# 毎時間ごとにjobを実行
schedule.every().hour.do(task)
# AM10:30にjobを実行
schedule.every().day.at("10:30").do(task)
# 月曜日にjobを実行
schedule.every().monday.do(task)
# 水曜日の13:15にjobを実行
schedule.every().wednesday.at("13:15").do(task)
ソースコード
# coding: UTF-8
import urllib.request, urllib.error
from bs4 import BeautifulSoup
from datetime import datetime
import schedule
import pandas as pd
import time
def task():
# 現在時刻を取得
nowTime = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
url = "http://news.livedoor.com/%E5%AE%87%E5%AE%99/topics/keyword/32398/"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
# コンテンツを取得
contents = soup.find_all("li")
columns = ["GetInformationDate", "Topic", "Link"]
df = pd.DataFrame(columns = columns)
print(nowTime)
for content in contents:
topic = content.find('h3')
if (topic != None):
link = content.find('a')
detailLink = link.get('href')
print('Title :' + str(topic.text) + 'Link :' + detailLink)
_csv = pd.Series([nowTime, str(topic.text), detailLink], columns)
df = df.append(_csv, columns)
# csv出力
csvFile = "result.csv"
df.to_csv(csvFile, encoding = 'utf-8-sig')
if __name__ == '__main__':
# 10分毎にjobを実行
schedule.every(10).minutes.do(task)
# 毎時間ごとにjobを実行
#schedule.every().hour.do(task)
# AM10:30にjobを実行
#schedule.every().day.at("10:30").do(task)
# 月曜日にjobを実行
#schedule.every().monday.do(task)
# 水曜日の13:15にjobを実行
#schedule.every().wednesday.at("13:15").do(task)
while True:
schedule.run_pending()
time.sleep(1)
最後に
pythonとscheduleライブラリを使った定期的なWebスクレイピング処理を紹介しました。
すごく簡単に実装出来るので、皆さんも是非試してみてください。
日常の生活ちょっとした手間をどんどん自動化していきましょう!