
目次
はじめに
最近は機械学習の解釈性がよく聞かれますが、そんな中でMicrosoft Researchがとても面白いかつ今後有用になりそうなライブラリを発表していました。
私はNorikazuYamadaさんのツイート*1でDiCEの存在を知りました。
本記事ではkaggleにあるローン審査のデータセットとDiCEを使ってローン審査の反事実を生成してみます。
なお、現時点ではDiCEは実装がまだしっかりと整備されていないため、今後実装が進んだ際は現時点とは使い方等が変わるかもしれませんのでご了承下さい。
DiCEとは
機械学習の解釈性を理解するために反事実モデルによるアプローチを使ったライブラリです。
反事実とは、「もし○○しなかったら」といったように事実の反対の事を指す用語で、因果推論といった分野でよく用いられる用語です。
詳細は公式ページ(GitHub, arXiv)をご参照ください。
- GitHub:Generate Diverse Counterfactual Explanations for any machine learning model
- arXiv:Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations
DiCEでローン審査の反事実を生成する
今回は、kaggleにあるLoan Prediction Problem Datasetを使ってローン審査の反事実を生成してみます。
まずはDiCEのインストール。
pip install dice-ml
DiCEは現時点ではTensorflowとPyTorch対応しかしていません。今回はTensorflowで実装します。
TensorflowのバージョンはDiCEのチュートリアルと同じ1.13.0-rc1に設定しておきます。
必要なライブラリのインポート
import dice_ml from dice_ml.utils import helpers # helper functions import numpy as np import pandas as pd import tensorflow as tf from tensorflow import keras tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR) print(tf.__version__) #1.13.0-rc1
データセットの読込み
train = pd.read_csv('./loan_train.csv')
print(train.shape)
display(train.head())
#(614, 13)

上図で見切れて見えていませんが、目的変数はLoan_Statusでローンが承認されたかどうか(Y or N)のバイバリ変数となっています
特徴量には使わないLoan_IDをこの段階で削除しておきます。
train = train.drop('Loan_ID', axis=1)
train.info()
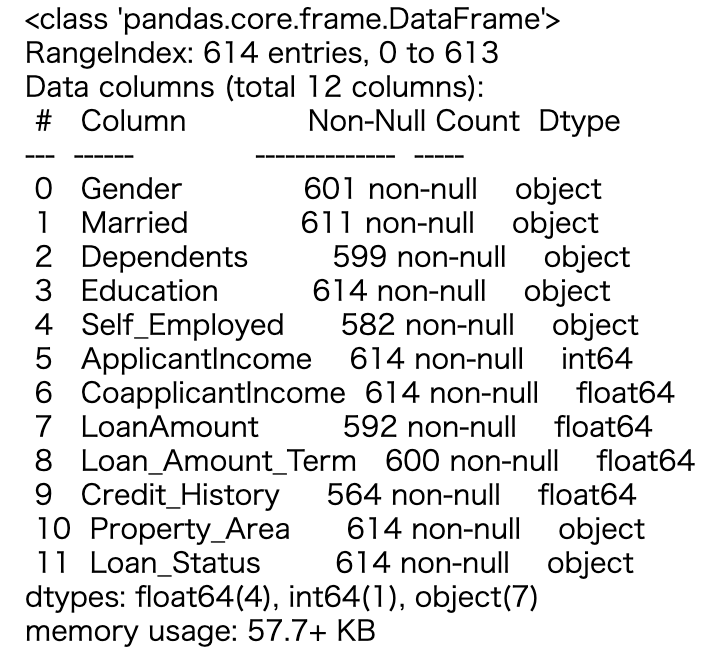
欠損値補完
各カラムは欠損値を持っているようなので、欠損値補完をします。
ここら辺の処理はkaggleのnotebookを参考にさせてもらってちゃちゃっと実装します。
カテゴリカル変数は最頻値で補完、数値は中央値で補完します。
cat_data = [] num_data = [] for i,c in enumerate(train.dtypes): if c == object: cat_data.append(train.iloc[:, i]) else : num_data.append(train.iloc[:, i]) cat_data = pd.DataFrame(cat_data).T num_data = pd.DataFrame(num_data).T cat_data = cat_data.apply(lambda x:x.fillna(x.value_counts().index[0])) num_data.fillna(num_data.median(), inplace=True)
次に、目的変数のLoan_Statusをバイナリ変数に変換します。
target_values = {'Y': 1 , 'N' : 0}
target = cat_data['Loan_Status']
cat_data.drop('Loan_Status', axis=1, inplace=True)
target = target.map(target_values)
データフレームの結合
最後に、カテゴリカル変数と数値のデータフレームを結合したデータフレームを作成します。
df = pd.concat([cat_data, num_data, target], axis=1) df.head()

dice_mlのDataクラスへインスタンス化
DiCEを使うためにインスタンス化します。この際、どのカラムが数値かを引数として指定する必要がありますので、指定してあげます。
ただ、現時点ではこの部分が注意が必要です。
本来であれば、5つのカラム(ApplicantIncome、CoapplicantIncome、LoanAmount、Loan_Amount_Term、Credit_History)が数値ですので、これらを指定すべきなのですが、現時点でのDiCEライブラリの実装だと反事実の生成部分でエラーが発生しています。
下図がエラー内容。
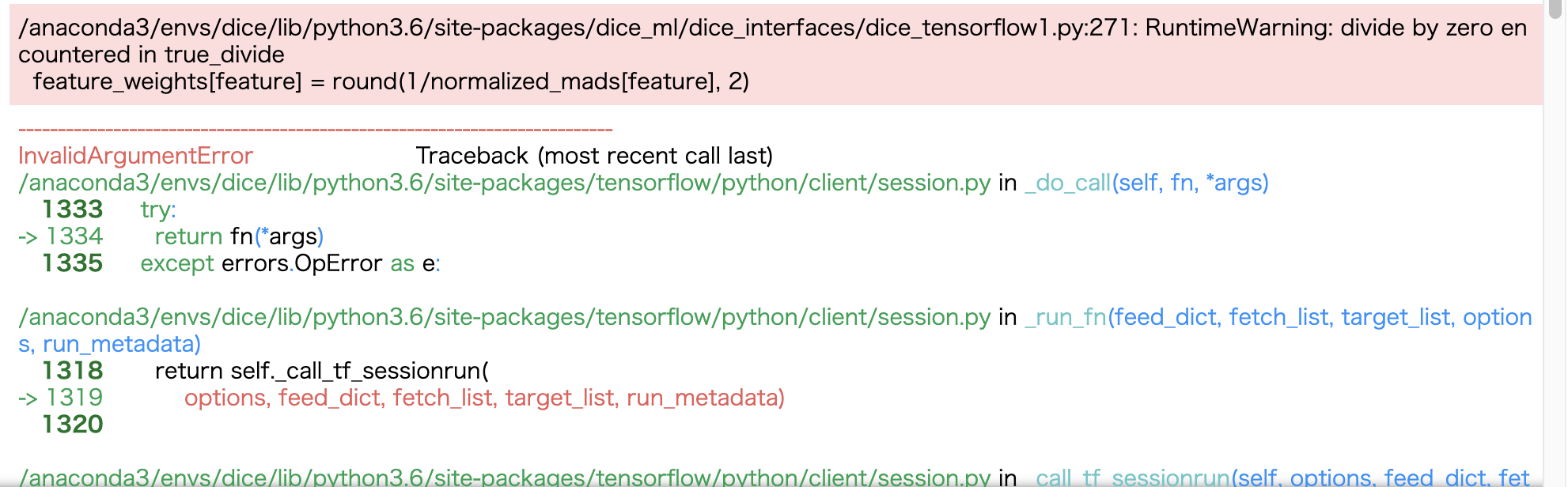
これはNorikazuYamadaさんが動画で説明されたように0除算が原因で起きるエラーで、論文中の式からもその可能性が伺えます。
その結果、今回は下のように3つのカラムを数値として与えて、それ以外はカテゴリカル変数として処理していきます。
今後こういった部分の改善も是非期待したいところです。
d = dice_ml.Data(dataframe=df, continuous_features=['ApplicantIncome','CoapplicantIncome','LoanAmount'], outcome_name='Loan_Status')
特徴量のOne-Hot化, モデルの学習
DiCEのチュートリアルにしたがってカテゴリカル変数のOne-Hot化して、20層のニューラルネットワークモデルを作成します。
sess = tf.InteractiveSession()
train, _ = d.split_data(d.normalize_data(d.one_hot_encoded_data))
X_train = train.loc[:, train.columns != 'Loan_Status']
y_train = train.loc[:, train.columns == 'Loan_Status']
ann_model = keras.Sequential()
ann_model.add(keras.layers.Dense(20, input_shape=(X_train.shape[1],), kernel_regularizer=keras.regularizers.l1(0.001), activation=tf.nn.relu))
ann_model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
ann_model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.01), metrics=['accuracy'])
ann_model.fit(X_train, y_train, validation_split=0.20, epochs=100, verbose=0, class_weight={0:1,1:2})
学習済モデルをDiCEクラスへ変換
# provide the trained ML model to DiCE's model object backend = 'TF'+tf.__version__[0] # TF1 m = dice_ml.Model(model=ann_model, backend=backend) # initiate DiCE exp = dice_ml.Dice(d, m)
反事実の生成
いよいよDiCEによる反事実の生成です。
今回は学習に使ったLoan_Statusが0になっているインデックス1のデータについて、4つの反事実を生成してみます。
factual_sample = df.iloc[1, 1:].to_dict() dice_exp = exp.generate_counterfactuals(factual_sample, total_CFs=4, desired_class='opposite') # visualize the resutls dice_exp.visualize_as_dataframe()
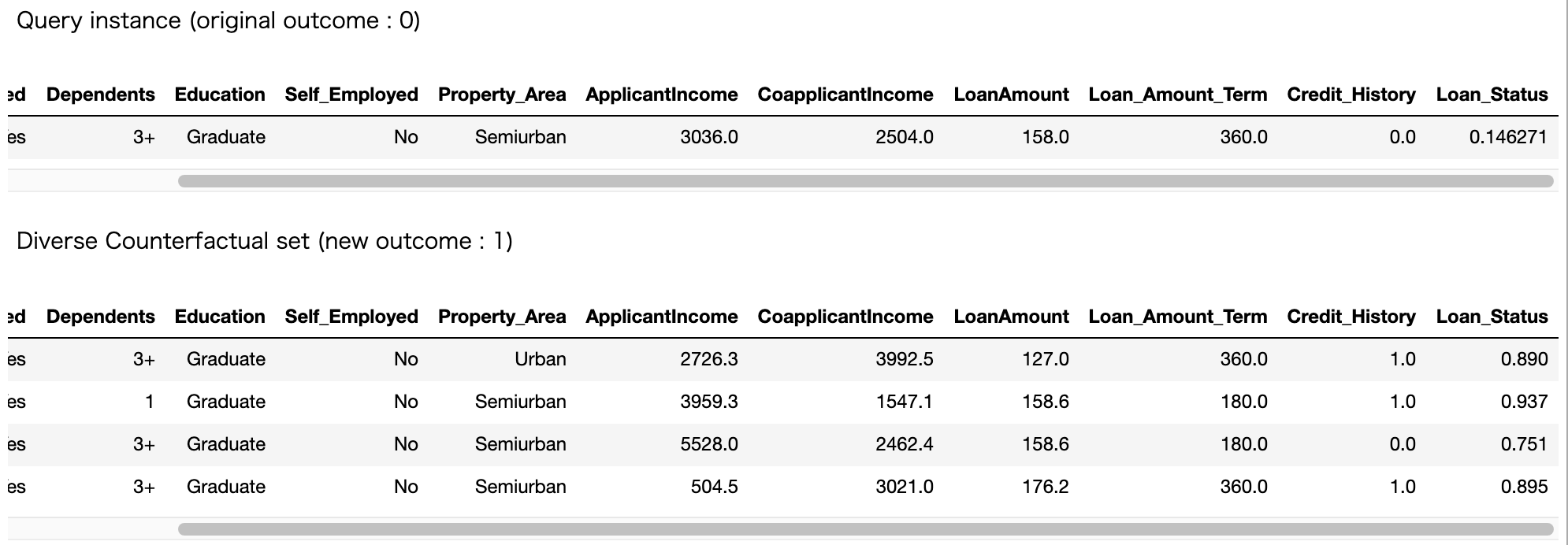
結果がこちらです。
Query instanceはインデックス1番のオリジナルデータが出力されていて、original outcomeが0でモデルが予測した値は0.146271となっています。
そしてDiCEが生成してくれた4つの反事実もしっかりと出力されています。
カラム数が多く全部はキャプチャー出来なかったのですが、例えば2番目の反事実シナリオであればローン審査の結果を1となる確率が0.937と飛躍的に向上することが読み取れます。
二番目のシナリオで特に着目すべきは下記のカラムになりますね。
ApplicantIncome(申請者の収入):3036.0 → 3959.3
CoapplicantIncome(共同申請者の収入):2504.0 → 1547.1
Loan_Amount_Term(1ヶ月単位での融資期間):360.0 → 180.0
Credit_Histrory(クレジット歴がガイドラインを満たしているか):0.0 → 1.0
これは非常に面白い。こういった反事実のシナリオがわかると確かに実務において特にビジネスサイドと議論する場合にかなり有用になりそうです。
おわりに
本記事では、DiCEを用いてローン審査のデータセットから反事実を生成してみました。
ライブラリとしての完成度やその他使い勝手はまだまだ改善の余地はありそうですが、ビジネスの現場で機械学習プロジェクトを進めていく上でとても可能性を秘めていそうです。
また、今回の実装はGitHubにも公開しています。
参考
*1:
NorikazuYamadaさんの動画解説はとてもわかりやすく、いつも参考にさせてもらっています。
DiCEの説明動画を撮りました。実装面が順調に進めば実務でもどんどん使いたい(順調に進めば)。https://t.co/uHFWYU7fu4 https://t.co/0T1Jlg68Qs
— NorikazuYamada (@NorikazuYamada) February 20, 2020
