
目次
はじめに
こんにちわ!やじろべえです!
最近、職場の蓄積したデータを使って顧客が離反するかしないかについて予測したいとビジネスサイドの方がフラグを立てている(?)らしいので、予習がてらにオープンデータセットを用いて機械学習的なアプローチで分析してみました。
データセット
今回はたまたまこちらのBlogを見つけたので、こちらのBlog記事に掲載されているデータセットを使いたいと思います。(後日kaggleでもよさげデータセットを見つけましたが、これはまた後日トライします。)
こちらのデータセットを開くと、性別(Gender)、年齢(Age)、支払方法(Payment Method)、離反(Churn)、最終購入日(Last Transaction)が各カラムに保存されています。今回は顧客が離反したかどうかの予測をしたいので、離反(Churn)カラムを目的変数とし、それ以外のカラムは説明変数として使います。レコード数は全部で996件あり、train:test = 8:2で分割して使うことにします。
探索的データ解析(EDA)
trainデータの中身を見ていきます。
まずは、性別(Gender)の割合がどれだけバラついているか確認してみます。
男性の方が少し割合が多いですが、男性と女性との間に大きな偏りは無さそうです。
df = pd.read_csv('customer-churn-data.csv')
train, test = train_test_split(df, test_size=0.2, random_state=42)
male_ratio = (train['Gender'].value_counts()[0]/train.shape[0])*100
female_ratio = (train['Gender'].value_counts()[1]/train.shape[0])*100
print('male[%]: ', male_ratio)
print('female[%]: ', female_ratio)
# male[%]: 54.2713567839196
# female[%]: 45.7286432160804
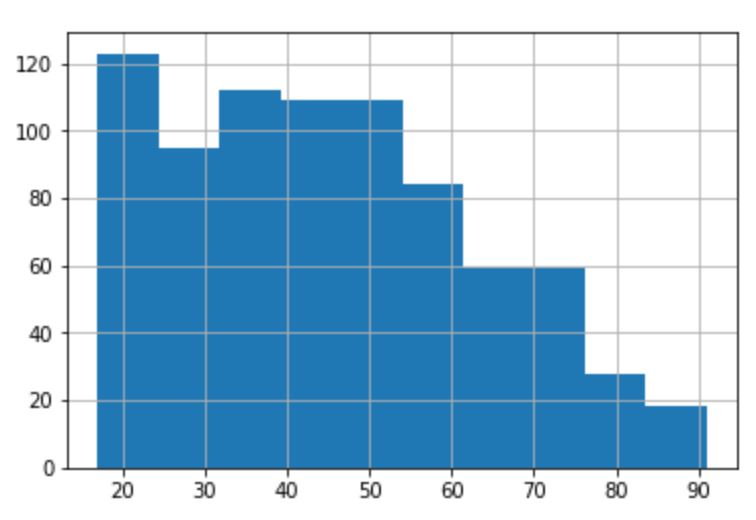
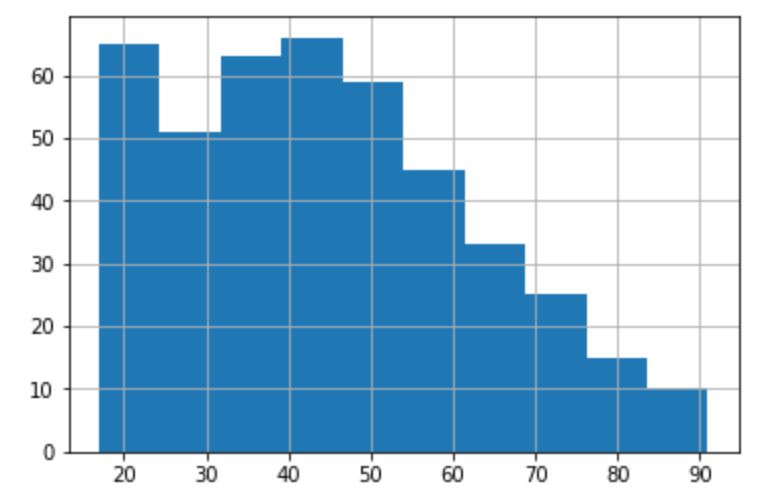
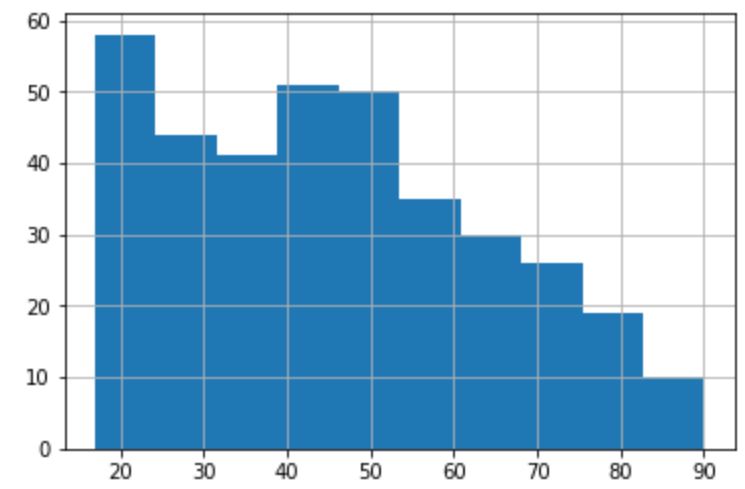
次に、年齢(Age)の確認ですが、データ全体の年齢の分布と男性、女性それぞれの分布を見てみます。男女間で大きな差は無さそうです。また、20代の層が最も多く、年齢が高くなるにつれて人数は少なくなっていくような傾向があるようです。
【データ全体の年齢ごとのヒストグラム】
【男性】
【女性】
支払方法についても見てみます。クレジットカードが最も多く、その次に現金で、小切手が最も少ないようです。
train['Payment Method'].value_counts() #credit card 523 #cash 220 #cheque 53
最終購入日(LastTransaction)については、110付近をピークにして、正規分布のような形を取っています。購入日となっているので、〇日前ということなのでしょうか。
次に、男性と女性で離反率にどれだけバラツキがあるかをクロス集計で確認してみます。女性の方が離反率が多く、男性の方が継続率が高いようです。
print(pd.crosstab(train['Gender'], train['Churn'], margins=True, normalize=True))

最後に、目的変数である離反もしくは継続の割合を確認します。
loyal_ratio = (train['Churn'].value_counts()[0]/train.shape[0])*100
churn_ratio = (train['Churn'].value_counts()[1]/train.shape[0])*100
print('loyal[%]: ', loyal_ratio)
print('churn[%]: ', churn_ratio)
# loyal[%]: 56.40703517587939
# churn[%]: 33.165829145728644
前処理
まずtrainデータに含まれる欠損値を確認します。どうやら目的変数のうち83レコードが欠損になっていて、それ以外の変数については欠損は含まれていないようです。
print('missing value->;Gender:', train['Gender'].isnull().sum())
print('missing value->;Age:', train['Age'].isnull().sum())
print('missing value->;Payment Method:', train['Payment Method'].isnull().sum())
print('missing value->;Churn:', train['Churn'].isnull().sum())
print('missing value->;LastTransaction:', train['LastTransaction'].isnull().sum())
# missing value->;Gender: 0
# missing value->;Age: 0
# missing value->;Payment Method: 0
# missing value->;Churn: 83
# missing value->;LastTransaction: 0
目的変数が欠損データなので、ひとまずこれらのレコードは削除してそれ以外のデータで学習します。
train = train.dropna(how='any')
説明変数と目的変数に分けておく。
train = train[['Gender','Age','Payment Method','LastTransaction', 'Churn']] X_train = train.iloc[:,:-1] # 最終列以前を特徴量X y_train = train.iloc[:,-1] # 最終列を正解データ
性別と支払方法はダミー化して、目的変数はバイナリー化。
ohe_columns = ['Gender', 'Payment Method']
X_train_new = pd.get_dummies(X_train,
dummy_na=True,
columns=ohe_columns)
# 離反客(churn)を1(正例)へ変換
class_mapping = {'churn':1, 'loyal':0}
y_train = y_train.map(class_mapping)
上記と同じ手順をtestデータでもやっておきます。
test = test[['Gender','Age','Payment Method','LastTransaction', 'Churn']]
print('missing value->;Gender:', test['Gender'].isnull().sum())
print('missing value->;Age:', test['Age'].isnull().sum())
print('missing value->;Payment Method:', test['Payment Method'].isnull().sum())
print('missing value->;Churn:', test['Churn'].isnull().sum())
print('missing value->;LastTransaction:', test['LastTransaction'].isnull().sum())
test = test.dropna(how='any')
X_test = test.iloc[:,:-1] # 最終列以前を特徴量X
y_test = test.iloc[:,-1] # 最終列を正解データ
ohe_columns = ['Gender', 'Payment Method']
X_test_new = pd.get_dummies(X_test,
dummy_na=True,
columns=ohe_columns)
# 離反客(churn)を1(正例)へ変換
class_mapping = {'churn':1, 'loyal':0}
y_test = y_test.map(class_mapping)
モデリング
今回はsklearnに実装されている、勾配ブースティングを使って精度を検証してみます。
from sklearn.ensemble import GradientBoostingClassifier as GBC from sklearn.metrics import classification_report clf = GBC() clf.fit(X_train_new, y_train) print(accuracy_score(y_train, clf.predict(X_train_new))) # 0.8877980364656382 y_pred = clf.predict(X_train_new) print(classification_report(y_train, y_pred))
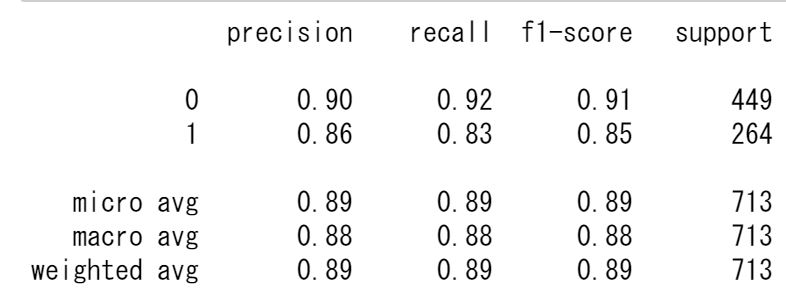
精度は88%程度、precision, recallも80%以上ですので、悪くない精度です。
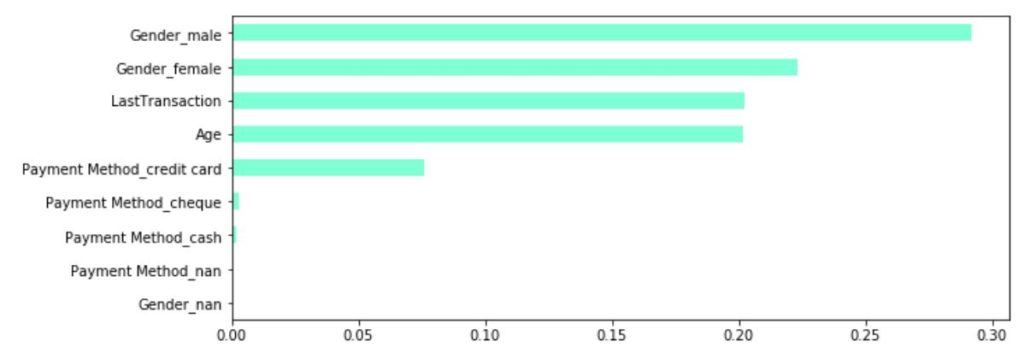
特徴量重要度も見てみます。性別が最も重要な変数となっているようです。EDAのクロス集計においても性別によって離反率に偏りがあることは把握していたのでモデルも同じような所に着目していることがわかります。
importances = clf.feature_importances_ feature_importance = pd.Series(importances,index=X_train_new.columns) feature_importance.sort_values().plot(kind='barh', figsize=(10, 4), color='aquamarine')
では、最後にtestデータを使って最終的にな精度を見てみます。
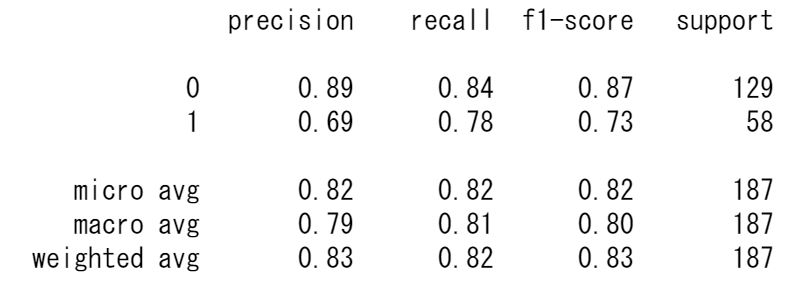
精度としては、82%程度なっていますので悪くない結果ですが、precisionとrecallがそこまで良い精度ではなさそうです。
y_test_pred = clf.predict(X_test_new) print(accuracy_score(y_test, clf.predict(X_test_new))) # 0.8235294117647058 print(classification_report(y_test, y_test_pred))
最後に
顧客離反予測モデルをやってみました。実務での開発時にはハイパーパラメータのチューニングや交叉検証などもっと細かく見るところは多々ありますが、ひとまず全体としての流れはこんな感じですかね。次はkaggleのデータセットを使ってやってみたいと思います。