
目次
はじめに
最近は機械学習やディープラーニングによる文字検出の精度が向上してますね。
本記事ではもっと古典的な文字検出方法を実装して、試してみたいと思います。
また、実装においてはOpenCVを使っていますが、画素へのアクセスや四角形の描画くらいでしか使っていませんので、その他のライブラリでも対応可能です。
ソースコードはGitHubにもあげました。
動作環境
・PyCharm Community Edition 2018.3.1 x64
・OpenCV 3.4.5.20
文字検出(文字領域抽出)とは
その名の通り、画像などに写った文字を検出する技術で、古くからたくさんの手法が提案されているようです。
似たようなものとして文字認識(OCR)という有名な技術があります。
両者の違いとしては、OCRは画像に写っている文字がどんな文字かを”認識して”テキストデータ等で出力してくれるのに対して、文字検出は、文字らしい領域が画像中のどこにあるのかを計算しその位置を出力してくれる技術です。
ただ、今はディープラーニングがすごい勢いで進化しているので、文字検出も文字認識もいっぺんにやってしまうような流れになっていくのかもしれません。
もしかしたら既にそういった技術があるのかもしれません。
そちらの分野について知見がある方がいましたら教えていただけると嬉しいです。
射影(投影)分布とは
ある画像をある方向に投影したときに計測される黒画素の度数分布のことです。
基本的なやり方として、垂直方向および水平方向に対して射影分布を算出し、分布の山となっている部分を文字らしきものが存在していると判断する手法です。
下の図はアルファベット”Z”の射影分布を計測したものです。
直感的にもわかりやすいですね。

スポンサーリンク

入力画像
今回はこちらの画像を使って、文字を検出してみたいと思います。
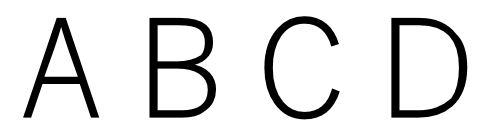
ソースコード
import cv2
import numpy as np
import matplotlib.pyplot as plt
def Projection_H(img, height, width):
array_H = np.zeros(height)
for i in range(height):
total_count = 0
for j in range(width):
temp_pixVal = img[i, j]
if (temp_pixVal == 0):
total_count += 1
array_H[i] = total_count
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
x_axis = np.arange(height)
ax.barh(x_axis, array_H)
fig.savefig("hist_H.png")
return array_H
def Projection_V(img, height, width):
array_V = np.zeros(width)
for i in range(width):
total_count = 0
for j in range(height):
temp_pixVal = img[j, i]
if (temp_pixVal == 0):
total_count += 1
array_V[i] = total_count
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
x_axis = np.arange(width)
ax.bar(x_axis, array_V)
fig.savefig("hist_V.png")
return array_V
def Detect_HeightPosition(H_THRESH, height, array_H):
lower_posi = 0
upper_posi = 0
for i in range(height):
val = array_H[i]
if (val > H_THRESH):
lower_posi = i
break
for i in reversed(range(height)):
val = array_H[i]
if (val > H_THRESH):
upper_posi = i
break
return lower_posi, upper_posi
def Detect_WidthPosition(W_THRESH, width, array_V):
char_List = np.array([])
flg = False
posi1 = 0
posi2 = 0
for i in range(width):
val = array_V[i]
if (flg==False and val > W_THRESH):
flg = True
posi1 = i
if (flg == True and val < W_THRESH):
flg = False
posi2 = i
char_List = np.append(char_List, posi1)
char_List = np.append(char_List, posi2)
return char_List
if __name__ == "__main__":
# input image
img = cv2.imread("./character.jpg")
# convert gray scale image
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# black white
ret, bw_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_OTSU)
height, width = bw_img.shape
# create projection distribution
array_H = Projection_H(bw_img, height, width)
array_V = Projection_V(bw_img, height, width)
# detect character height position
H_THRESH = 5
lower_posi, upper_posi = Detect_HeightPosition(H_THRESH, height, array_H)
# detect character width position
W_THRESH = 2
char_List = Detect_WidthPosition(W_THRESH, width, array_V)
# draw image
if (len(char_List) % 2) == 0:
print("Succeeded in character detection")
for i in range(0, (len(char_List)-1), 2):
img = cv2.rectangle(img, (int(char_List[i]), int(upper_posi)), (int(char_List[i+1]), int(lower_posi)), (0,0,255), 2)
cv2.imwrite("result.jpg", img)
else:
print("Failed to detect characters")
結果
まずは射影分布の確認をしてみます。
水平方向の分布では文字列、垂直方向では各文字で山となることが確認出来ます。

分布が山になっている部分だけに着目すれば文字が検出出来そうです。
ということで、文字位置に赤い枠で囲ってみました。
見事に文字だけの部分が検出出来ました。

まとめ
射影(投影)分布による文字検出をやってみました。
正直な話、このくらい処理しやすい画像であれば、この手法を使わなくても、ラベリング処理でも上手くいきますね。
射影分布と文字形状情報を組み合わせることで、文書の文字を検出することも出来そうです。
時間あるときにまたチャレンジしてみたいと思います。
今回はここまで。
参考文献
・制約充足に基づく文書画像からの文字領域抽出に関する研究
・日本語文中の英文字の認識手法の開発 – 阿曽研究室
人気記事
スポンサーリンク
