
目次
はじめに
kaggleで宇宙に関係する面白そうなコンペをあるイベントを通して知ったので、早速チャレンジしてみました。
今回チャレンジしたコンペは既に終了していますが、大変興味深く面白かったので記事に残しました。
kaggleとは
世界中の機械学習やデータサイエンスに携わっている約40万人の方が集まるコミュニティです。
Kaggleにはコンペと呼ばれるものが数多く開催されています。
Kaggleで行われているコンペでは、企業や国の研究機関がデータセットを提供し、
世界中のデータサイエンティスト等が精度を競い合います。
コンペによっては多額の賞金が支払われることもあります。
今回チャレンジしたコンペ
Solar Radiation Predictionにチャレンジしてみました。
このコンペを選んだ理由として、私は以前、宇宙放射線計測業務に従事していた経験もあり、太陽からの放射線予測であれば私のこれまでの知見が生かせるだろうと思っていたからです。
しかし!分析を進めれば進めるほど、「このコンペ、放射線と関係なくね?」って気づきました。
後ほど生データの一部を紹介しますが、地球の気象データ(温度や風向き、風の強さなど)しか無く、放射線の要素がいっさい感じられない。。
ちゃんとコンペの内容を読み込んでみると、どうやら”Solar radiation = 日射量”っぽいことが判明!
最初にちゃんと内容読み込まないとダメですね。。
つまり日射量を予測して太陽光発電に応用したい的なコンペだということがわかりました。
でも、これはこれで面白そう。
にしても紛らわしい!!それとも、私が知らないだけ?(汗)`
詳しい方がいらっしゃいましたら是非教えてください。
ということで、私の経験はあまり生かせなさそうなテーマだとわかりましたが、せっかくここまで内容を理解してきたので、何はともあれやってみよう!
スポンサーリンク
データの可視化
最初から自力でやるのは大変なので、まずはいくつかのカーネルを参考にデータの可視化を行ってみました。
まずは、必要なライブラリのインポートとデータセットの中身を見てみます。
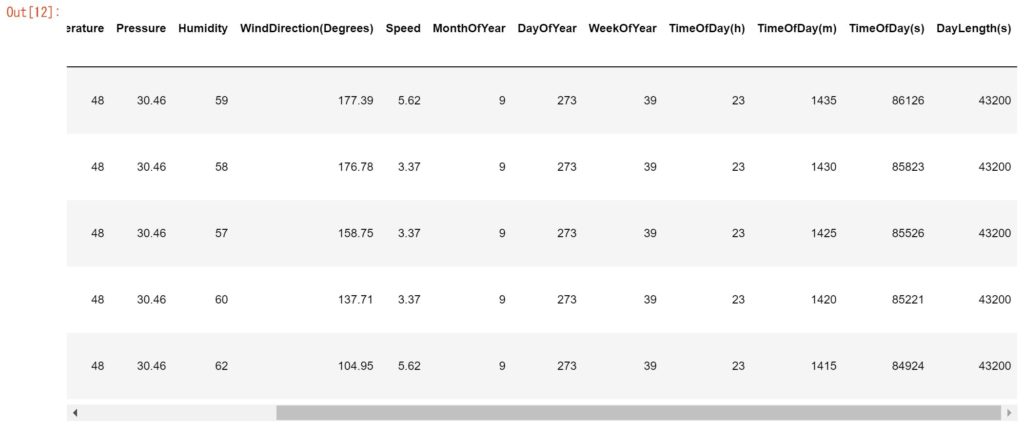
import numpy as np import matplotlib.pyplot as plt import seaborn as sns import pandas as pd data_path = "./" dataset = pd.read_csv(data_path+"SolarPrediction.csv") dataset.head()

UNIXTimeは聞きなれない人もいるかもですが、これはコンピュータ時間とも呼ばれていて、世界時間(UTC)1970年1月1日午前0時0分0秒から計測した経過時間(秒)のことですね。
そして、Radiationというのが実際に計測された日射量(W)になります。
その他に与えられてるパラメータとして、温度、気圧、湿度、風速、日の出時刻、日没時刻となっています。
次に、UNIXTimeを使って時刻を分解してもう少し時間に特徴情報を付加してみます。
from datetime import datetime
from pytz import timezone
import pytz
hawaii= timezone('Pacific/Honolulu')
dataset.index = pd.to_datetime(dataset['UNIXTime'], unit='s')
dataset.index = dataset.index.tz_localize(pytz.utc).tz_convert(hawaii)
dataset['MonthOfYear'] = dataset.index.strftime('%m').astype(int)
dataset['DayOfYear'] = dataset.index.strftime('%j').astype(int)
dataset['WeekOfYear'] = dataset.index.strftime('%U').astype(int)
dataset['TimeOfDay(h)'] = dataset.index.hour
dataset['TimeOfDay(m)'] = dataset.index.hour*60 + dataset.index.minute
dataset['TimeOfDay(s)'] = dataset.index.hour*60*60 + dataset.index.minute*60 + dataset.index.second
dataset['TimeSunRise'] = pd.to_datetime(dataset['TimeSunRise'], format='%H:%M:%S')
dataset['TimeSunSet'] = pd.to_datetime(dataset['TimeSunSet'], format='%H:%M:%S')
dataset['DayLength(s)'] = dataset['TimeSunSet'].dt.hour*60*60 \
+ dataset['TimeSunSet'].dt.minute*60 \
+ dataset['TimeSunSet'].dt.second \
- dataset['TimeSunRise'].dt.hour*60*60 \
- dataset['TimeSunRise'].dt.minute*60 \
- dataset['TimeSunRise'].dt.second
dataset.drop(['Data','Time','TimeSunRise','TimeSunSet'], inplace=True, axis=1)
dataset.head()
最後にこれらのデータを使ってデータを視覚化してみましょう。
今回は1時間毎、月毎の平均データを可視化して確認してみました。
grouped_m=dataset.groupby('MonthOfYear').mean().reset_index()
grouped_w=dataset.groupby('WeekOfYear').mean().reset_index()
grouped_d=dataset.groupby('DayOfYear').mean().reset_index()
grouped_h=dataset.groupby('TimeOfDay(h)').mean().reset_index()
f, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8)) = plt.subplots(4, 2, sharex='col', sharey='row', figsize=(14,12))
ax3.set_ylim(45,60)
ax5.set_ylim(30.36,30.46)
ax7.set_ylim(60,85)
ax1.set_title('Mean Radiation by Hour')
pal = sns.color_palette("YlOrRd_r", len(grouped_h))
rank = grouped_h['Radiation'].argsort().argsort()
g = sns.barplot(x="TimeOfDay(h)", y='Radiation', data=grouped_h, palette=np.array(pal[::-1])[rank], ax=ax1)
ax1.set_xlabel('')
ax2.set_title('Mean Radiation by Month')
pal = sns.color_palette("YlOrRd_r", len(grouped_m))
rank = grouped_m['Radiation'].argsort().argsort()
g = sns.barplot(x="MonthOfYear", y='Radiation', data=grouped_m, palette=np.array(pal[::-1])[rank], ax=ax2)
ax2.set_xlabel('')
ax3.set_title('Mean Temperature by Hour')
pal = sns.color_palette("YlOrRd_r", len(grouped_h))
rank = grouped_h['Temperature'].argsort().argsort()
g = sns.barplot(x="TimeOfDay(h)", y='Temperature', data=grouped_h, palette=np.array(pal[::-1])[rank], ax=ax3)
ax3.set_xlabel('')
ax4.set_title('Mean Temperature by Month')
pal = sns.color_palette("YlOrRd_r", len(grouped_m))
rank = grouped_m['Temperature'].argsort().argsort()
g = sns.barplot(x="MonthOfYear", y='Temperature', data=grouped_m, palette=np.array(pal[::-1])[rank], ax=ax4)
ax4.set_xlabel('')
ax5.set_title('Mean Pressure by Hour')
pal = sns.color_palette("YlOrRd_r", len(grouped_h))
rank = grouped_h['Pressure'].argsort().argsort()
g = sns.barplot(x="TimeOfDay(h)", y='Pressure', data=grouped_h, palette=np.array(pal[::-1])[rank], ax=ax5)
ax5.set_xlabel('')
ax6.set_title('Mean Pressure by Month')
pal = sns.color_palette("YlOrRd_r", len(grouped_m))
rank = grouped_m['Pressure'].argsort().argsort()
g = sns.barplot(x="MonthOfYear", y='Pressure', data=grouped_m, palette=np.array(pal[::-1])[rank], ax=ax6)
ax6.set_xlabel('')
ax7.set_title('Mean Humidity by Hour')
pal = sns.color_palette("YlOrRd_r", len(grouped_h))
rank = grouped_h['Humidity'].argsort().argsort()
g = sns.barplot(x="TimeOfDay(h)", y='Humidity', data=grouped_h, palette=np.array(pal[::-1])[rank], ax=ax7)
ax8.set_title('Mean Humidity by Month')
pal = sns.color_palette("YlOrRd_r", len(grouped_m))
rank = grouped_m['Humidity'].argsort().argsort()
g = sns.barplot(x="MonthOfYear", y='Humidity', data=grouped_m, palette=np.array(pal[::-1])[rank], ax=ax8)
plt.show()
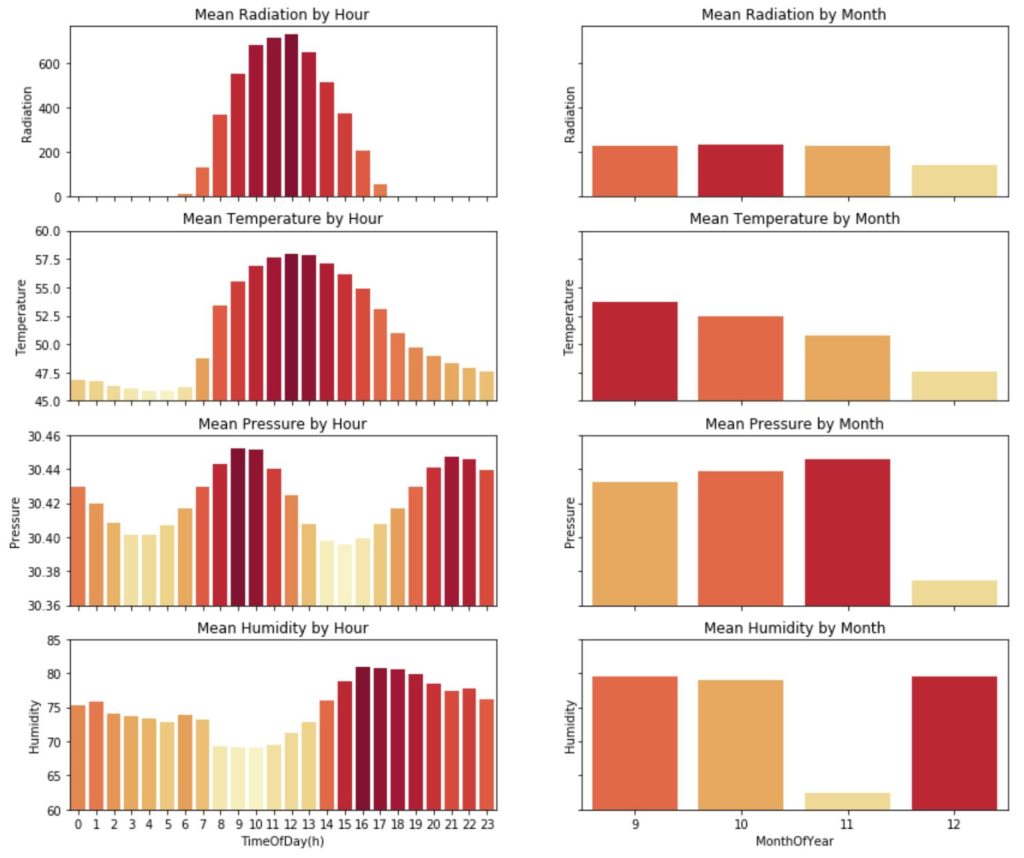
これを見てみると、当たり前ですが太陽の日射量と気温の相関関係が強いですね。
12時~13時付近で日射量と気温が最高値になっている点もなんとなく合っていそうですね。
そして、湿度は日射量や温度、気圧と負の相関がありそうです。
ここまでは他の人のカーネルをそのまま使わせてもらいました。
kaggleの素晴らしいところはこういうところにありますよね。
では、次からいよいよ機械学習でモデル作って精度を算出してみましょう!
モデルの生成・精度検証
ここからは少し自分なりに工夫して、モデルを作ってそのモデルの精度を検証してみたいと思います。
カーネルをいくつか見ると、線形回帰分析だったりランダムフォレストだったり色々なアルゴリズムを試していました。
結局どのアルゴリズムが一番精度良いかがよくわからなかったので、私はsklearnのPipelineを使って力技でたくさんのアルゴリズムで一気にモデルを作って精度を算出してみたいと思います。
まずはデータセットに変数を入れます。
今回は目的変数がRadiation(日射量)で、説明変数は下記を使いました。
X = dataset[['Temperature', 'Pressure', 'Humidity', 'WindDirection(Degrees)', 'Speed', 'DayOfYear', 'TimeOfDay(s)']] y = dataset['Radiation']
そのために、データをトレインデータとテストデータに8:2に分割します。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.pipeline import Pipeline
from sklearn.metrics import r2_score
# hold-out
X_train,X_test,y_train,y_test = train_test_split(X,
y,
test_size=0.20,
random_state=1)
# pipeline setting
pipelines = {
'ols': Pipeline([('scl',StandardScaler()),
('est',LinearRegression())]),
'ridge':Pipeline([('scl',StandardScaler()),
('est',Ridge(random_state=0))]),
'tree': Pipeline([('scl',StandardScaler()),
('est',DecisionTreeRegressor(random_state=0))]),
'rf': Pipeline([('scl',StandardScaler()),
('est',RandomForestRegressor(random_state=0))]),
'gbr1': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(random_state=0))]),
'gbr2': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(n_estimators=250,
random_state=0))])
}
# build and evaluate
scores = {}
for pipe_name, pipeline in pipelines.items():
pipeline.fit(X_train, y_train)
scores[(pipe_name,'train')] = r2_score(y_train, pipeline.predict(X_train))
scores[(pipe_name,'test')] = r2_score(y_test, pipeline.predict(X_test))
pd.Series(scores).unstack()
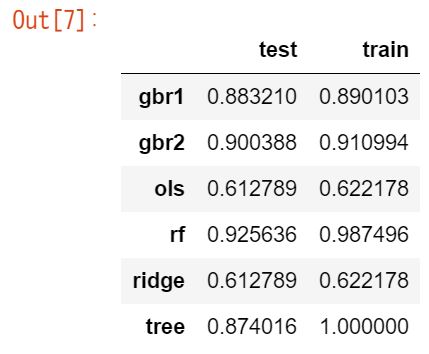
ただ、トレインデータと少し値の差が大きいのが気になるところ。過学習気味か?
ちなみに、kaggleのコンペでもランダムフォレストが精度良い結果が出てましたね。
最後に
UFOのデータとか隕石とかもあったので時間あるときにチャレンジしてみたいと思います。
オススメ書籍

[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)