
こんにちわ!やじろべえです。
今回は因果推論シリーズの第三弾として、回帰分析を使ってバイアスの影響を測定してみます。
これまでの因果推論記事は下記をご覧下さいませ。

これまでと同様に教科書は下記の書籍を参考にしています。因果推論をビジネス利用する観点で書かれており、現場でデータ分析する人は読んでおいて損は無いと思います。
これまでと同様に、データセットはMineThatData E-Mail Analytics And Data Mining Challenge datasetを使います。今回も検証の簡略化のため、女性向けのメール配信データは削除し、介入グループは男性向けメール配信ユーザーに限定します。
目次
データの読込と女性向けメール配信レコードの削除
import pandas as pd
import numpy as np
from scipy import stats
import statsmodels.api as sm
df = pd.read_csv('./MineThatData_E-MailAnalytics.csv')
mens_df = df[df['segment'] != 'Womens E-Mail']
 
# 男性向けにメール配信があったユーザーにフラグ付け
mens_df['treatment'] = 0
mens_df['treatment'].where(mens_df['segment'] != 'Mens E-Mail', 1, inplace=True)
バイアスのあるデータの作成
効果検証入門に書かれているように、メール配信を担当する担当者が購買傾向が一定以上あるユーザーに重点的にメール配信したと仮定します。そのような状況を再現するためのデータを作成します。
具体的には、メールが配信されていないグループには次の3つの条件のいずれかに該当するデータをランダムに半分選んで削除。一方でメールが配信されているグループは同じ条件に該当しないデータをランダムに半分選んで削除。
- 昨年の購入額が300より高い(history > 300)
- 最後の購入が6より小さい(recency < 6)
- 接触チャンネルが複数ある(channel = Multichannel)
# メール配信の担当者が購買傾向が一定以上あるユーザーに重点的にメール配信をした状況を再現するデータセットの作成 bias_rules = (mens_df['history'] &amp;gt; 300) | (mens_df['recency'] &amp;lt; 6) | (mens_df['channel'] == 'Multichannel') biased_df = pd.concat([ &amp;nbsp;&amp;nbsp;&amp;nbsp;&amp;nbsp;mens_df[(bias_rules) &amp;amp; (mens_df.treatment == 0)].sample(frac=0.5, random_state=1), &amp;nbsp;&amp;nbsp;&amp;nbsp;&amp;nbsp;mens_df[(bias_rules) &amp;amp; (mens_df.treatment == 1)], &amp;nbsp;&amp;nbsp;&amp;nbsp;&amp;nbsp;mens_df[(~bias_rules) &amp;amp; (mens_df.treatment == 0)], &amp;nbsp;&amp;nbsp;&amp;nbsp;&amp;nbsp;mens_df[(~bias_rules) &amp;amp; (mens_df.treatment == 1)].sample(frac=0.5, random_state=1) ], axis=0, ignore_index=True)
RCTデータとバイアスのあるデータ単回帰分析
セレクションバイアスが存在する場合、回帰分析を用いることでその影響を取り除く事が出来ます。
一方でセレクションバイアスが小さくなるように回帰分析を行うためには、共変量を正しく選ぶ事が重要になります。
まずは、RCTで得られたデータとセレクションバイアスが存在するデータで回帰分析を行い、結果にどのような違いがあるかを見てみます。
- RCTデータ
X = mens_df[['treatment']] X = sm.add_constant(X) y = mens_df['spend'] model_rct = sm.OLS(y, X) results_rct = model_rct.fit() summary = results_rct.summary() rct_reg_coef = summary.tables[1] rct_reg_coef
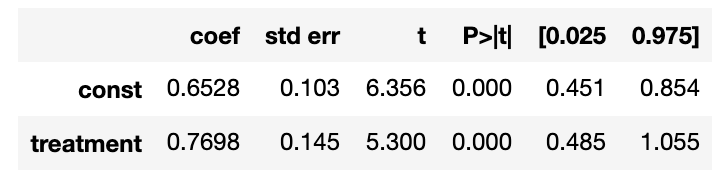
- セレクションバイアスのあるデータ
X = biased_df[['treatment']] X = sm.add_constant(X) y = biased_df['spend'] model_biased = sm.OLS(y, X) results_biased = model_biased.fit() summary = results_biased.summary() biased_reg_coef = summary.tables[1] biased_reg_coef
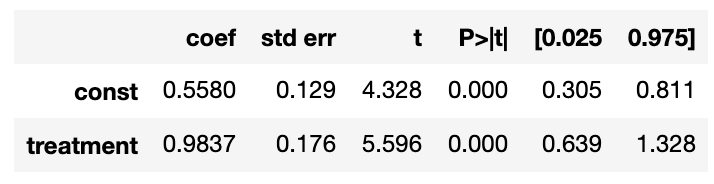
それぞれの回帰係数(coef)を見てみると、RCTで割付けされたデータの結果(0.7698)よりもバイアスのあるデータの結果(0.9837)の方が大きい結果となっていますので、セレクションバイアスによって効果が大きく推定されたことがわかります。
バイアスのあるデータで重回帰分析
今回準備したセレクションバイアスのあるデータは、history, recency, channelの三つの変数を使って作成しました。そこでこれらの変数を回帰分析する際の共変量に加えて重回帰分析を行うことで、結果がどのようになるか見てみます。
X = pd.get_dummies(biased_df[['treatment', 'recency', 'channel', 'history']], columns=['channel'], drop_first=True) X = sm.add_constant(X) y = biased_df['spend'] model_biased = sm.OLS(y, X) results = model_biased.fit() summary = results.summary() biased_reg_coef = summary.tables[1] biased_reg_coef
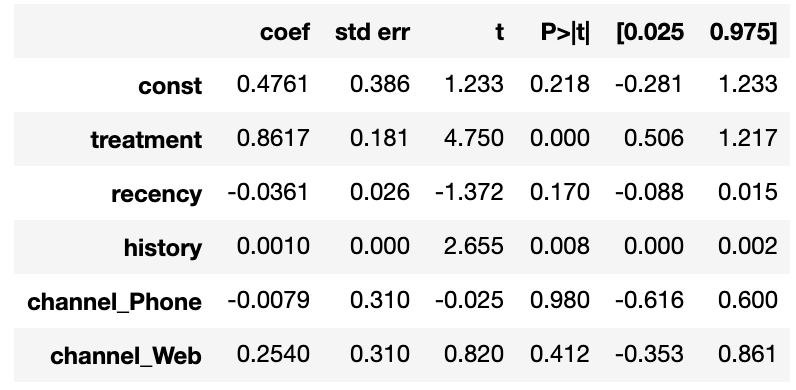
結果を見てみると、treatmentの回帰係数が0.8617となり、単回帰分析の結果より値が低くなりました。また、完全では無いもののRCTデータにおける単回帰分析の結果に近づくことが確認出来ました。
まとめ
効果検証入門を参考にして、介入効果を計るための回帰分析を行いました。
バイアスのあるデータで回帰分析を行うと結果も過剰に推定されるので注意が必要ですね。
バイアスが発生し得るデータについては、重回帰分析を使うといった工夫が必要。
参考書籍
- 効果検証入門(正しい比較のための因果推論/計量経済学の基礎)
