
こんちにわ!都内のスタートアップでデータ分析しているやじろべえです。
新型コロナウィルスの影響が拡大していますね。昨日はついに緊急事態宣言まで出されてまだまだ収束の目処は立っていないように見えますね。
さて、最近は機械学習の解釈性がよく話題になっていますが、今回はこの機械学習の解釈性について一つのソリューションを与えてくれるSHAPについて試してみました(もうN番煎じなんだよって感じですが・・・)。
目次
SHAPとは
SHAP(SHapley Additive exPlanations)は、協力ゲーム理論で使われるシャープレイ値を用いることで機械学習モデルで算出された予測値が各変数からどのくらいの影響を受けたかを算出するものです。元論文はこちら。
また、SHAPはPythonパッケージも開発されていて、みんな大好きpip installで簡単に使えます。ビジュアライズがとてもパワフルなところも良いですね。
協力ゲーム理論の話やシャープレイ値について詳しいことを知りたい方は下記が参考になると思います。


インストール
pipコマンド一発でインストール可能です。
pip install shap
データセットの準備と前処理
今回は実務でSHAPを使う場合を想定したいので、データセットもそれっぽいものを使ってみました。
使ったのはこちらの顧客離反予測データセット。
import shap
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
shap.initjs()
df = pd.read_csv("./WA_Fn-UseC_-Telco-Customer-Churn.csv")
df.dtypes
#customerID object
#gender object
#SeniorCitizen int64
#Partner object
#Dependents object
#tenure int64
#PhoneService object
#MultipleLines object
#InternetService object
#OnlineSecurity object
#OnlineBackup object
#DeviceProtection object
#TechSupport object
#StreamingTV object
#StreamingMovies object
#Contract object
#PaperlessBilling object
#PaymentMethod object
#MonthlyCharges float64
#TotalCharges object
#Churn object
#dtype: object
こちらのデータセットは説明変数が20あり、目的変数がChurnというカラムのバイナリ変数となっています。
また、説明変数の多くがカテゴリカルなのでとりあえず何も考えず欠損値は’NONE’で埋めて、カテゴリカル変数はラベルエンコーディングしてしまいます。
# 欠損値をNONEで埋める
df['customerID'] = df['customerID'].fillna('NONE')
df['gender'] = df['gender'].fillna('NONE')
df['SeniorCitizen'] = df['SeniorCitizen'].fillna('NONE')
df['Partner'] = df['Partner'].fillna('NONE')
df['Dependents'] = df['Dependents'].fillna('NONE')
df['tenure'] = df['tenure'].fillna('NONE')
df['PhoneService'] = df['PhoneService'].fillna('NONE')
df['MultipleLines'] = df['MultipleLines'].fillna('NONE')
df['InternetService'] = df['InternetService'].fillna('NONE')
df['OnlineSecurity'] = df['OnlineSecurity'].fillna('NONE')
df['OnlineBackup'] = df['OnlineBackup'].fillna('NONE')
df['DeviceProtection'] = df['DeviceProtection'].fillna('NONE')
df['TechSupport'] = df['TechSupport'].fillna('NONE')
df['StreamingTV'] = df['StreamingTV'].fillna('NONE')
df['StreamingMovies'] = df['StreamingMovies'].fillna('NONE')
df['Contract'] = df['Contract'].fillna('NONE')
df['PaperlessBilling'] = df['PaperlessBilling'].fillna('NONE')
df['PaymentMethod'] = df['PaymentMethod'].fillna('NONE')
df['MonthlyCharges'] = df['MonthlyCharges'].fillna('NONE')
df['TotalCharges'] = df['TotalCharges'].fillna('NONE')
df['TotalCharges'] = df['TotalCharges'].fillna('NONE')
# 目的変数のバイナリ化
class_mapping = {'No':0, 'Yes':1}
df['Churn'] = df['Churn'].map(class_mapping)
# 説明変数のラベルエンコーディング
from sklearn import preprocessing
encode_list = ['customerID',
'gender',
'Partner',
'Dependents',
'PhoneService',
'MultipleLines',
'InternetService',
'OnlineSecurity',
'OnlineBackup',
'DeviceProtection',
'TechSupport',
'StreamingTV',
'StreamingMovies',
'Contract',
'PaperlessBilling',
'PaymentMethod',
'TotalCharges']
for column in encode_list:
print(column)
le = preprocessing.LabelEncoder()
le.fit(df[column])
df[column] = le.transform(df[column])
モデルの作成
# trainとvalidに分ける train_data, valid_data = train_test_split(df, test_size=0.2, random_state = 1) y_train = train_data["Churn"] X_train = train_data[["gender", "SeniorCitizen", "Partner", "Dependents", "tenure", "PhoneService", "MultipleLines", "InternetService", "OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies", "Contract", "PaperlessBilling", "PaymentMethod", "MonthlyCharges", "TotalCharges"]] # モデルの作成 clf = xgb.XGBClassifier() clf.fit(X_train, y_train) #予測 from sklearn.metrics import accuracy_score y_valid = valid_data["Churn"] X_valid = valid_data[["gender", "SeniorCitizen", "Partner", "Dependents", "tenure", "PhoneService", "MultipleLines", "InternetService", "OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies", "Contract", "PaperlessBilling", "PaymentMethod", "MonthlyCharges", "TotalCharges"]] pred = clf.predict(X_valid) print(accuracy_score(np.round(pred),y_valid)) #0.8140525195173882
はい、これで適当なモデルが出来上がりました。
では次にいよいよSHAPを使ってみます。
SHAPを使ってみる
#SHAPの準備 explainer = shap.TreeExplainer(model=clf) shap_values = explainer.shap_values(X=X_valid)
ここまでで一通りの準備が出来ました。SHAPによる結果を可視化してみます。
Force Plot
まずはモデルが解約すると予測したユーザーがSHAPでどのような結果になるか見てみます。
これはforce_plot()を使います。
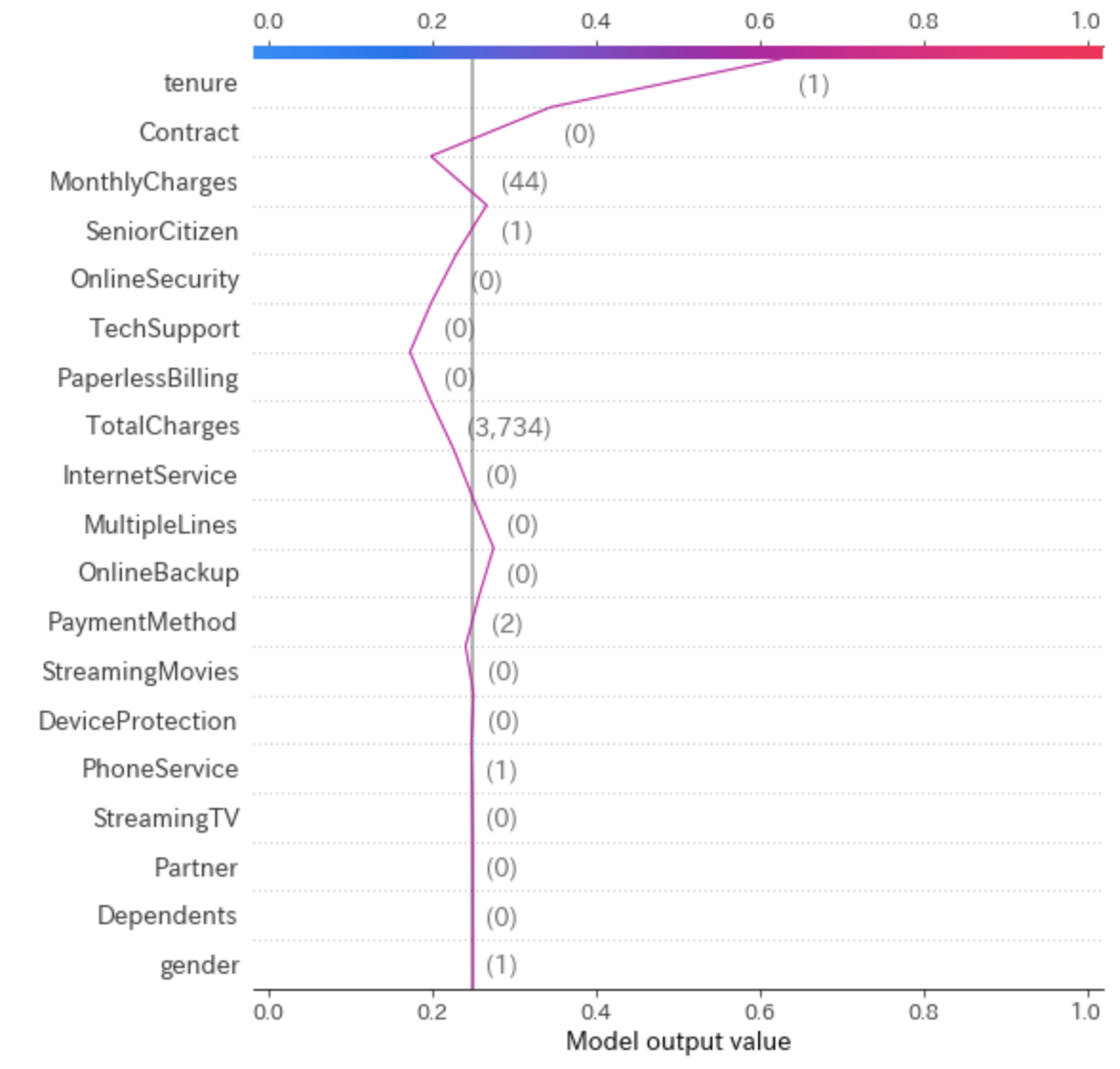
i = 7 shap.force_plot(explainer.expected_value, shap_values[i, :], X_valid.iloc[i,:], link="logit")

なぜこのような予測結果になったかについて、シャープレイ値で各変数を分解して可視化しています。
このケースではtenure=1となっていて、これが解約に大きく寄与している(プラスの要因)ことがわかります。一方で、MonthlyCharges=44は解約しないことに寄与している(マイナスの要因)と見て取れます。
ユーザーをまとめて見たい場合は下記のように範囲を指定するとまとめて表示してくれます。
s = 0 e = 200 shap.force_plot(explainer.expected_value, shap_values[s:e, :], X_valid.iloc[s:e, :], link="logit")
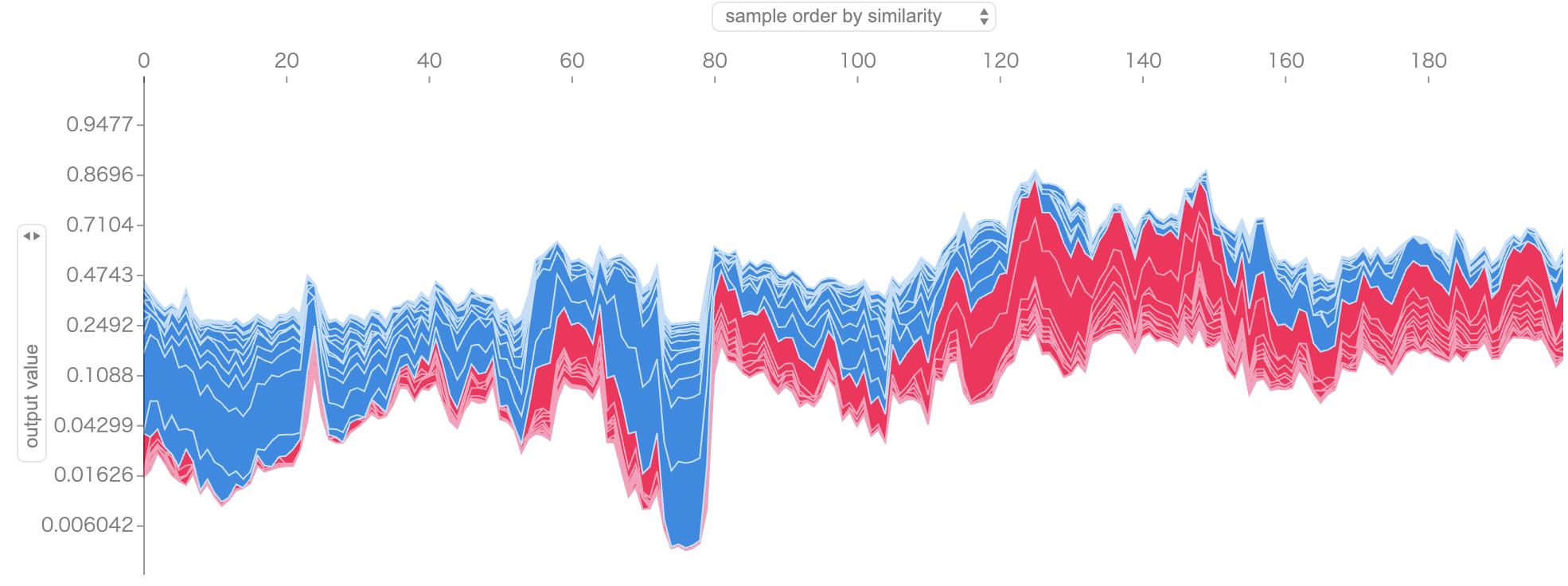
Decision Plot
force_plot()よりも更に詳しく各変数の影響を知りたいときに便利なのが、decision_plot()です。
misclassified = (np.round(pred) != y_valid) shap.decision_plot(explainer.expected_value, shap_values[7:8], X_valid[7:8], link="logit",highlight=misclassified[0:1])
Summary Plot
先ほどまでは一人のユーザーに対して各変数がどのような値を取っていたかを見ましたが、もう少しマクロな分析をしたい場合は各変数のシャープレイ値をプロットする事も出来るsummary_plot()を使います。
shap.summary_plot(shap_values, X_valid)
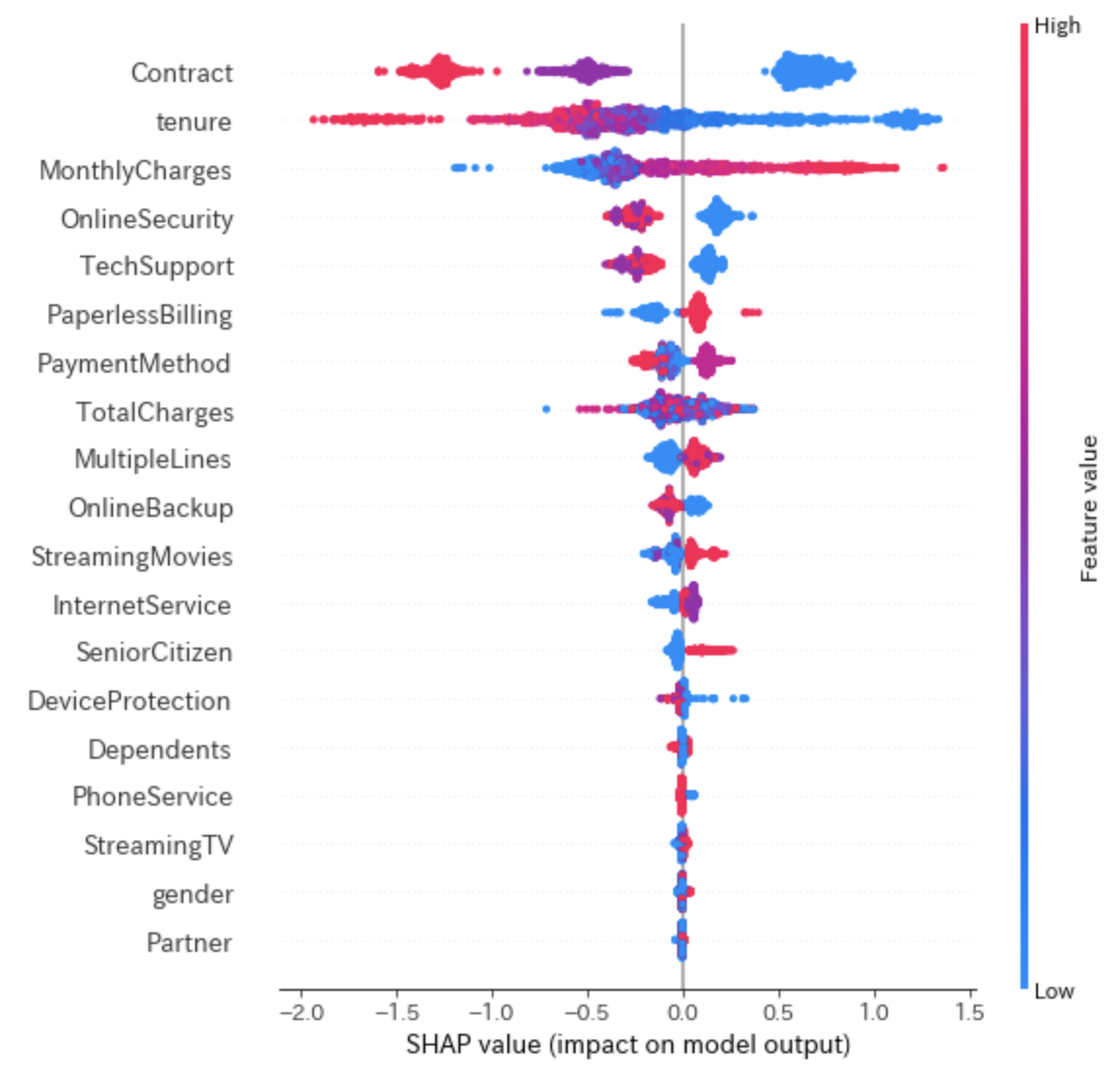
上の方にある変数ほど予測に重要な変数で、これを見るとContractが青色の点がSHAP値の正の方に多く分布していて、赤色の点はSHAP値の負の方に多く分布しています。同じようにtenureについても確認すると、SHAP値が大きくなるほど青い分布となり、SHAP値が小さくなるほど赤い分布となっているので、負の相関であることがわかります。
実務ではどう使えそうか?
特にビジネスサイドがこれまで離反しないであろうと考えていた顧客に対して、予測モデルが離反すると予測した場合は「なぜ離反予測したのか?」と当然疑問を持つしデータ分析サイドに聞かれることになるのでそういったケースにおいては、ある一定の根拠で説明出来る材料になりそうですね。
最後に
今回は機械学習の解釈性について一つのソリューションとなるSHAPを試してみました。
この記事ではツリーベースモデルで試しましたが、SHAPは線形モデルやニューラルネットのアルゴリズムでも使えます。
また、テーブルデータ以外にも画像データにも使えるので興味ある方は試してみてはいかがでしょうか。
